Problem Statement: Design a Machine Learning system to generate Facebook news feed (Questions like Instagram, TikTok or Twitter news feed is a subset of this question).
Clarifying Questions
- Do we have a social network similar to Facebook with people having friends and pages they follow?
- If there is an existing social network like Facebook, we would have data regarding posts, user interactions, social network, etc. readily available to us.
- Is there an existing system in place?
- If there is an existing system in place, then we have a baseline to compare our new ML system. If there isn’t one, we could quickly setup a heuristic-based system where we fetch posts from friends/followed pages and sort them in reverse chronological order.
- How many users are going to use this application?
- This would help us understand the scale that we are dealing with. If we are dealing at Facebook scale, it’s going to be around 1.6 billion daily active users.
Business Objective
- Improve user engagement/user satisfaction, meaningful social interactions.
- User engagement and user satisfaction could be a combination of likes, comments, shares, reports and survey responses.
- Meaningful social interactions capture posts that inspire back-and-forth discussion in the comments and posts that you might want to share and react.
Requirements
- Training
- User preferences may change regularly and new posts may become popular. So we need to train our model regularly. We could start with weekly training and change it to multiple times a week if the improvements in metrics justify the extra infrastructure costs.
- Inference
- For every user to visit the homepage, the system will have to a newsfeed consisting of hundreds of posts. The latency needs to be under 200ms, ideally sub 100ms.
- For post recommendations, it’s important to find the right balance between exploration vs exploitation. If the model over-exploits historical data, new types of posts might not get exposed to users, leading to a lack of diversity. We want the right balance between relevancy and new posts.
Give an overview of the various components to discuss at this point: Training data, Feature Engineering, Modelling, Evaluation, Deployment and monitoring. Then proceed talking about each component. This shows organisation and structure to your approach, more typical of senior candidates.
Training Data
Data collection
- User Profiles: We could gather user profile data, including demographic information, location, age, gender, and any self-reported interests or preferences. User profiles help understand the characteristics of users and can be used to personalise the newsfeed based on their individual attributes.
- Social Connections: We could capture data about the social connections between users, such as friend relationships, groups, and pages followed. Social connections provide insights into the social graph and can be leveraged for content recommendations, such as prioritising posts from friends or groups to which a user is connected.
- User Interactions: We could collect data on user interactions with the platform, such as likes, comments, shares, and clicks. This data provides valuable signals about user preferences, interests, and engagement patterns. We could capture information about the types of content users interact with, the frequency of interactions, and the context in which they occur.
- Content Metadata: We could collect metadata about the content posted on Facebook, including information such as text descriptions, captions, hashtags, publishing time, and content type (text, image, video). This metadata helps in understanding the nature of the content and its relevance to users.
- External Signals: We could incorporate external signals that provide additional context for content relevance. This may include trending topics, popular hashtags, news events, or user engagement patterns at a larger scale. External signals help capture real-time trends and enhance the newsfeed’s responsiveness to current interests and discussions.
- Implicit Feedback: We could capture implicit feedback signals from users’ actions and behaviour on the platform. This can include information such as the time spent viewing a post, scrolling behaviour, hover actions, or dwell time. Implicit feedback helps understand user engagement and preferences without relying solely on explicit feedback.
- Privacy Considerations: We need to ensure that the data collection process adheres to privacy regulations and user consent. We should respect user privacy preferences and anonymise personal data when necessary. We should implement robust data protection measures to secure user information and maintain data privacy.
- Data Sampling: We could consider appropriate sampling techniques to collect representative data from a diverse user base. We need to ensure that the collected data covers a wide range of user preferences, interests, and behaviours to capture a comprehensive understanding of the user population.
- Data Quality and Cleaning: We should clean the collected data to remove noise, outliers, duplicates, and irrelevant information. We may perform data quality checks to ensure the accuracy and consistency of the collected data. We should preprocess the data, such as normalising text, handling missing values, and resolving inconsistencies, to prepare it for analysis and modelling.
Data labelling
- Relevance Labels: Relevance labels indicate the relevance of a post to a specific user. They can be binary (e.g., relevant or irrelevant) or multi-level (e.g., highly relevant, somewhat relevant, not relevant). Relevance labels help the system understand the user’s preferences and ensure that the content displayed is aligned with their interests. This can be used when filtering relevant posts to be ranked for a user. We could obtain this using historical interactions of users with various posts. A post which the user clicked, commented, liked or shared can be labelled as relevant and other posts with impression or posts the user reported as irrelevant.
- Engagement Labels: These labels indicate the level of user engagement with a particular post, such as likes, comments, shares, or clicks. Higher engagement labels indicate more positive user responses, while lower engagement labels represent less interaction. These labels help model user preferences for content that is likely to generate higher engagement. We could obtain these labels using historical interactions of users with various posts.
- Quality Labels: These labels identify posts that are considered spam, low-quality, clickbait, sensationalised health claims, misinformation, etc. These may be violating platform guidelines in one way or the other. They can be obtained through user reports, content moderation systems, or automated spam detection algorithms. Quality labels help filter out undesirable or inappropriate content from the newsfeed.
- Diversity Labels: Diversity labels provide information about the diversity of content in the newsfeed. They can indicate whether a post represents a different viewpoint, topic, or format compared to the user’s existing content consumption patterns. Diversity labels help ensure that the newsfeed presents a variety of perspectives and avoids filter bubbles.
Feature Engineering
- Features
- User only
- gender, age, location, demographics, metadata, user_interests, user_historical_views (posts with views), user_historical_likes (posts with likes), user_historical_reports, user_historical_comments, user_historical_shares, user_historical_posts, known_languages, user_historical_searches, device, user_language, interests, pages_followed, groups_joined, time_spent_on_platform, user_historical_liked_topics
- Post only
- author, author_followers_count, author_posts_count, author_weekly_posts_count, length, time_of_post, post_type (photo/video/carousel/link), post_language, number_of_views, number_of_likes, number_of_comments, number_of_shares, number_of_reports, clicks_in_last_24_hours, clicks_in_last_7_days, likes_in_last_24_hours, likes_in_last_7_days, comments_in_last_24_hours, comments_in_last_7_days, shares_in_last_24_hours, shares_in_last_7_days, reports_in_last_24_hours, reports_in_last_7_days, uploaded_time (age_of_post), number_of_impressions, impressions_in_last_24_hours, impressions_in_last_7_days, post_contents (including text, image captions, images, etc.)
- User-author interaction features
- number_of_author_posts_liked, number_of_author_posts_shared, number_of_author_posts_commented, number_of_author_posts_reported, number_of_author_posts_liked_last_month, number_of_author_posts_shared_last_month, number_of_author_posts_commented_last_month, number_of_author_posts_reported_last_month, number_of_author_posts_liked_last_week, number_of_author_posts_shared_last_week, number_of_author_posts_commented_last_week, number_of_author_posts_reported_last_week, are_friends, number_of_common_friends, connection_age (how long has the user been connected to the author)
- Context features
- time_of_the_day, day_of_the_week, season_of_the_year, is_holiday_season, month, upcoming_holidays, trending_topics
- User only
- Feature types and featurisation techniques:
- Textual Features: like post textual contents, image captions, user metadata, etc.
- Bag-of-Words (BoW): Represent text content as a vector of word frequencies or presence/absence indicators. Use techniques like TF-IDF (Term Frequency-Inverse Document Frequency) to weight the importance of words.
- Word Embeddings: Utilise pre-trained word embeddings like Word2Vec, GloVe, or FastText to capture semantic relationships between words.
- N-grams: Consider sequences of words to capture local context and phrases.
- Topic Modelling: Apply techniques like Latent Dirichlet Allocation (LDA) to extract topics from text and represent documents in terms of their topic distributions.
- Sentiment Analysis: Extract sentiment features from text, indicating the emotional tone or polarity of the content.
- Numeric features
- For numeric features like clicks, number_of_views, number_of_likes, number of comments, number_of_author_posts_liked, etc., first we would want to look at missing values and handle them.
- If a feature has too many missing values, we could consider removing the column. However, this might remove some important information and reduce the accuracy of the model.
- Also, if a sample has missing values, we could remove that row. This method can work when the missing values are completely at random and the number of examples with missing values is small.
- Even though deletion is tempting because it’s easy to do, deleting data can lead to losing important information and introduce biases into the model. We could fill missing values with default value or using mean, median or mode.
- It’s important to scale the features before inputting it into a model. We could do min-max scaling: x’ = (x – min(x)) / (max(x) – min(x)), which would output the values in the range: [0, 1]. Standardisation is another option which would make the values have zero mean and unit variance: x’ = (x – mean(x)) / std(x).
- A thing to note here is that posts by celebrity authors would usually have a very high like/comment/share and impression count. This could be captured by the model, but if we see that the model always recommends posts by celebrity authors, we could use the ratio of like to impression instead of using raw count values.
- Categorical features
- For categorical features like gender, language, month, season_of_the_year, etc., we could use One Hot Encoding. This would lead to complex computation and high memory usage for categories with high cardinality, if we are building a large scale system. Also, new categories may appear in production, and marking all of them into one category (others) may not be optimal.
- We could use the hashing trick to encode categorical features, by using a hash function to generate a hashed value of each category. The hashed value will become the index of that category. Because we can specify the hash space, we can fix the number of encoded values for a feature in advance, without having to know how many categories there will be, enabling new categories to appear in production without any issues.
- Collision is a problem with hash functions, especially in cases of small hash size. We can increase the hash size, but that will consume more memory. With hash function, the collisions are random and the impact of collided features isn’t bad in most cases.
- Image features
- We could featurise the image to help us understand the content better. We could make use of pre-trained Convolutional Neural Networks for this.
- We could either use these features directly into the main model, or have a separate model that infers the image category, sentiment, etc. and use that as a feature in the main model.
- We could also use image descriptors (like SIFT) to capture low-level visual features of images, such as colour, texture or shape.
- Video features
- We could use frame-level features, by sampling some frames from the video and featurising them using image featurisation techniques.
- We could also use 3D CNNs to featurise the video.
- We could have a separate model which classifies the video into different categories using these features and gives the sentiment of the video to be used as a feature in the main model. This would avoid doing the heavy lifting of video featurisation in the main model.
- Textual Features: like post textual contents, image captions, user metadata, etc.
Modelling
Overall System:
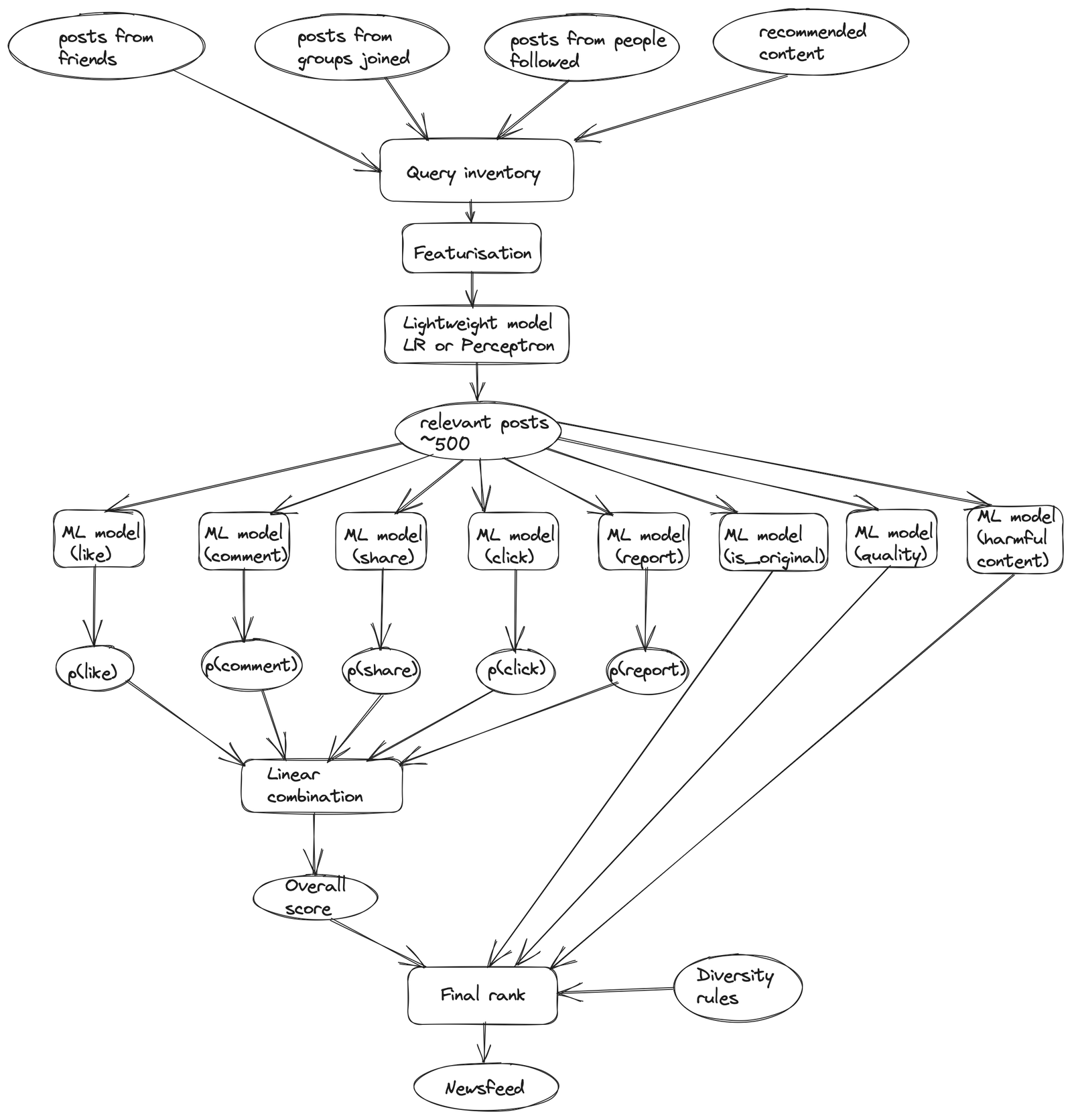
We can think of Feed Aggregator as the service that fetches posts, aggregates, ranks and returns the resulting list of ranked feed stories to the front end for rendering. Under the hood, we could have multiple ML models working in parallel.
Candidate posts
- We first need to collect all the candidate posts we can possibly rank.
- The eligible inventory includes any non-deleted posts shared with a person by a friend, group, or page that he/she is connected to that was made since his/her last login.
- There could be posts created before the person’s last login that hasn’t been seen yet, which could be of higher quality or more relevant than the newer posts.
- To make sure unseen posts are also reconsidered, we can use an unread bumping logic: Fresh posts that the person has not yet seen but that were ranked for him in his previous sessions can be made eligible again for him/her to see.
- We can also include an action-bumping logic: If any posts the person has already seen have triggered an interesting conversation among his friends, he/she may be eligible to see this post again as a comment-bumped post.
Lightweight model
- In pass 0, a lightweight model is run to select approximately 500 of the most relevant posts for the viewer that are eligible for ranking.
- We could just use a perceptron to classify the posts as relevant or irrelevant and randomly select around 500 relevant posts. Perceptrons are simple and fast linear models, but don’t output class probabilities and randomly selecting relevant posts might be sub-optimal.
- Instead, we could use Logistic Regression which are fast linear models and provide class probabilities as well, which could be used to select around 500 relevant posts with high probabilities.
- This would help us rank fewer stories with high recall in later passes so that we can use more powerful neural network models.
Main scoring
- Pass 1 would be the main scoring pass, where each story is scored independently by a number of ML models in parallel like p(like), p(comment), etc. (each modelling a different ML problem) and then all ~500 eligible posts are ordered by score.
- Most of the personalisation happens in here.
- We want to optimise how we combine the various model scores into a final score. For some, the score may be higher for likes than for commenting, as some people like to express themselves more through liking than commenting.
- For simplicity and tractability, we score our predictions together in a linear way. Note that this linear formulation has an advantage: Any action a person rarely engages in (for instance, a like prediction that’s very close to 0) automatically gets a minimal role in ranking.
Final pass
- Finally, we would have pass 2, which is the contextual pass.
- Here, contextual features, such as content-type diversity rules, could be added to help diversify the News Feed.
- We would also filter out unoriginal or harmful contents and look at post quality.
Evaluation and Deployment
- Evaluation metrics
- Offline metrics:
- For the lightweight relevance model:
- Accuracy: For most users, we would select around 500 posts from a few thousand posts. We could use accuracy as a measure here as the data is not that imbalanced.
- Precision
- It tells us what proportion of positive identifications was actually correct.
 .
.- We are not very concerned by False Positives here. It’s all right to have a few posts that might not be very relevant. This would be ranked lower anyways by the other models and would also add some diversity.
- Recall
- It tells us what proportion of actual positives was identified correctly.
 .
.- It’s vital that user’s don’t miss relevant posts, so we need to minimise False Negatives, hence optimise on recall.
- For p(like), p(comment), p(share), p(click), p(report) models:
- MAP@k (Mean Average Precision)
- It gives insight into how relevant the list of recommended items are.
 , where
, where  if
if  item is relevant else
item is relevant else  ,
,  = precision for top i recommendations, m = total number of relevant recommendations.
= precision for top i recommendations, m = total number of relevant recommendations.- MAP@k = mean of AP@k
- MAR@k (Mean Average Recall)
- It gives insight into how well the recommender is able to recall all the items the user has rated positively.
 , where if item is relevant else ,
, where if item is relevant else ,  = recall for top i recommendations, m = total number of relevant recommendations.
= recall for top i recommendations, m = total number of relevant recommendations.- MAR@k = mean of AR@k
- NDCG (Normalised Discounted Cumulative Gain)
- It is a measure of the effectiveness of a ranking system, taking into account the position of relevant items in the ranked list. It is based on the idea that items that are higher in the ranking should be given more credit than items that are lower in the ranking.
- Cumulative Gain,
 , where
, where  is the graded relevance of the result at position i. The value computed with the CG function is unaffected by changes in the ordering of search results. That is, moving a highly relevant document
is the graded relevance of the result at position i. The value computed with the CG function is unaffected by changes in the ordering of search results. That is, moving a highly relevant document  above a higher ranked, less relevant, document
above a higher ranked, less relevant, document  does not change the computed value for CG.
does not change the computed value for CG. - Discounted Cumulative Gain(DCG) accumulated at a particular rank position is defined as:

- Posts result lists vary in length depending on the number of posts returned by the relevance model. Comparing a model’s performance from one person to another cannot be consistently achieved using DCG alone, so the cumulative gain at each position for a chosen value of p should be normalised across queries.
 , where IDCG is ideal discounted cumulative gain.
, where IDCG is ideal discounted cumulative gain. , where
, where  represents the list of relevant documents (ordered by their relevance) in the corpus up to position p.
represents the list of relevant documents (ordered by their relevance) in the corpus up to position p.
- MAP@k (Mean Average Precision)
- For the lightweight relevance model:
- Online metrics:
- Click-through rate (CTR), Like rate, Comment rate, Share rate, Time Spent, User Engagement, User Satisfaction, Meaningful Social Interactions
- These could be directly tied back to the business objective.
- Offline metrics:
- Setup train, test, validate partitions (to prevent overfitting)
- We could split the 30-day training data we have into training, validation and test set. Sequence is important here, so we could use the first 20 days of data for training, next 5 days for validation and the last 5 days for testing.
- A/B test setup
- We could use the existing model as control group and the new model as test group.
- In a big company, many people may be running A/B experiments with their candidate models. It’s important to make sure our results are not getting affected by other experiments. It’s good to create multiple universes consisting of external users where all experiments corresponding to a particular feature/project are run in the same universe. Inside a universe, an external user can only be assigned to one experiment, thus making sure multiple experiments from the same universe won’t influence each other’s results.
- After doing sanity check for any config errors, we route half the traffic to control group and wait for a week before analysing the results.
- We could use chi-squared test or two-sample test to see if the results are statistically significant and decide whether the new model improves on the previous model.
- Debugging offline/online metric movement inconsistencies
- It’s important to continuously monitor the ML system and have health checks in place and alerts enabled.
- We should ideally have dashboards showing the important metrics (both business and performance) and changes in these metrics over time.
- If these metrics go below a certain threshold, we should have an alerting system in place to notify the correct team.
- We should also have logging in place, which would help with debugging these issues.
- A common cause of drop in model performance is data distribution shift, when the distribution of data the model runs inference on changes compared to the distribution of data the model was trained on, leading to less accurate models.
- We could work around the problem of data distribution shift either by training the model on a massive training dataset with the intent that the model learns a comprehensive distribution, or by retraining the model (from scratch or fine-tuning) to align with the new distribution.
- Edge cases can also make the model make catastrophic mistakes and need to be kept in mind when debugging.
