As we saw in the previous section, when doing hash-based sharding, adding or removing servers would need updating the mappings. Consistent hashing solves the horizontal scalability problem by ensuring that every time we scale up or down, we do not have to re-arrange all the keys or touch all the database servers.
Consistent hashing is a special kind of hashing technique such that when a hash table is resized, only n/m keys need to be remapped on average where n is the number of keys and m is the number of slots.
Imagine a virtual ring or circle, often represented as a circle with a range of values, typically from 0 to 2^32 (or some other large number). Each node in the distributed system, such as web servers, database servers or cache nodes, is also mapped onto this ring. When a piece of data, often identified by a unique key, needs to be stored or retrieved, it is hashed to produce a value within the range of the ring. This hashed value determines where the data should be placed /retrieved on the ring.
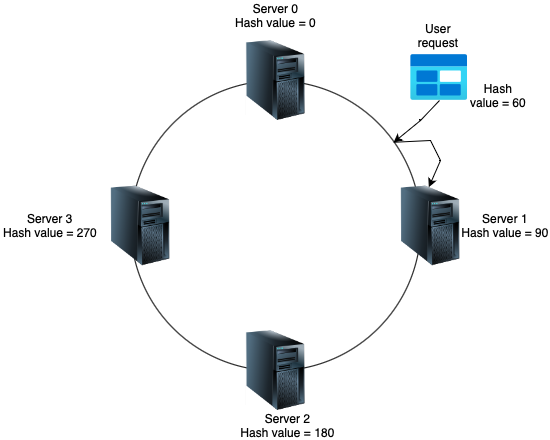
Each node on the ring is responsible for a portion of the ring’s hashed keys. This assignment is typically determined by a consistent hashing algorithm. When a data item needs to be stored or retrieved, it is hashed to find its position on the ring. And it gets assigned to the next node on the ring in clockwise direction. This ensures that data is evenly distributed across the nodes in the system.
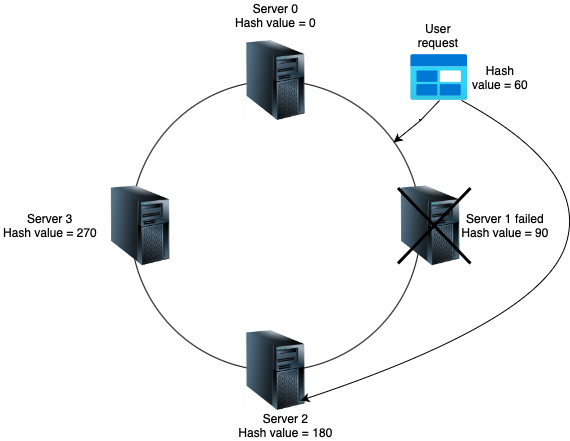
If a node fails or is removed from the system, only a portion of the data needs to be redistributed. This is because the consistent hashing algorithm minimises the data that needs to be moved when nodes are added or removed. Consistent hashing naturally provides load balancing because data is distributed evenly across nodes. When nodes are added or removed, only a fraction of the data needs to be redistributed, preventing hotspots and minimising disruption.
Consistent hashing has several advantages:
- Scalability: It scales well with the addition or removal of nodes, as only a fraction of the data needs to be moved.
- Load Balancing: Data is distributed evenly, reducing the risk of hotspots and ensuring efficient resource utilisation.
- Fault Tolerance: It provides fault tolerance because when a node fails, only a portion of the data is affected.
- Predictability: It allows for predictable data placement, making it easier to reason about the system’s behaviour.
- Minimised Data Movement: When nodes change, only a fraction of the data needs to be relocated, minimising network and computational overhead.
Consistent hashing is widely used in distributed systems, including distributed databases, content delivery network (CDN), and distributed caching systems, to provide efficient and fault-tolerant data distribution and retrieval.