Problem Statement: Design a cloud storage service like Dropbox, Google Drive, Microsoft OneDrive, Apple iCloud, etc.
Clarifying Questions
- How many users do we expect?
- 100 million DAU (Daily Active Users).
- Are we building a mobile app or a web app?
- Both.
- Which file formats are supported?
- Any file type.
- Do files need to be encrypted?
- Yes.
- Is there any size limit on files?
- Yes, files should be less than 10 GB in size.
- Do we need to support offline editing?
- Yes.
- Can users see previous versions of the file?
- Yes.
- Can users share the file with other users?
- Yes, users can share the file with specific users or make it visible to everyone.
- Can two users edit the same file simultaneously?
- This use-case is allowed in the system and needs to be handled in the design.
Requirements
- Functional requirements
- Users should be able to upload and download their files/photos from multiple devices including phone, laptop, iPad, etc.
- Users should be able to share files or folders with other users.
- There should be automatic synchronisation between devices.
- The system should support storing large files up to 10 GB.
- Our system should support offline editing. When online, these offline changes should be synchronised to remote servers and other online devices.
- Users should be able to see file revisions.
- Users should be notified when a relevant file is edited, deleted or shared with them.
- Non-functional requirements
- Our system should be highly reliable, as data loss is unacceptable here.
- Synchronisation should be quick. If it takes too much time, users may not be happy and switch to a different product.
- It’s important not to take a lot of unnecessary network bandwidth, as some users may be on limited mobile data plan.
- Our system should be able to handle large amount of traffic.
- Our system should be highly available.
Back-of-the-envelope estimation
- Traffic
- Daily Active Users (DAU) = 100 million
- Let’s assume, each user is connected from 2 devices and upload 10 files/photos daily on average.
- File uploads per day = 1 billion
- File uploads per sec = 11500 (approx.)
- Let’s assume a 1:1 read-write ratio.
- File downloads per sec = 11500 (approx.)
- Storage
- Let’s assume that average file size is 1 MB.
- Total storage for a day = 1 MB x 1 billion = 1 PB
- We will need to store the files forever, unless one of the authorised users decide to delete it. Total storage for 10 years = 1 PB x 365 x 10 = 3.65 EB (Exabyte)
- Please note that we did not take compression, replication, etc. into consideration in the above calculation.
- Bandwidth
- We have approximately 11500 file reads per second, and each file is assumed to be approximately 1 MB in size, so outgoing bandwidth = 11.5 GB/sec.
- And, we have approximately 11500 file uploads per second, and each file is assumed to be approximately 1 MB in size, so incoming bandwidth = 11.5 GB/sec.
System APIs
file_upload(auth_token, userID, upload_type, data)
- auth_token: Used for authenticating API requests.
- userID: current user id.
- upload_type:
- simple: For small files.
- resumable: For large files, where there may be network interruptions. We could use the following steps here:
- Initial request to fetch resumable URL.
- Start data upload and monitor upload status.
- If the upload was interrupted, resume the upload.
- data: Local file to be uploaded.
- Returns upload status (completed, interrupted, failed)
file_download(auth_token, userID, path)
- auth_token: Used for authenticating API requests.
- userID: current user id.
- path: download file path.
- Returns the file to be downloaded, or error code in case of any error.
file_revisions(auth_token, userID, path, limit)
- auth_token: Used for authenticating API requests.
- userID: current user id.
- path: File path for which you want to get the revision history.
- limit: Maximum number of revisions to return.
- Returns file revisions, or error code if there is any error.
Database
User table
- UserID
- Name
- Email id
- Profile photo
- Account creation timestamp
- Membership Tier
- Total storage used
- Total storage available
Device table
- DeviceId
- UserId
- Last login timestamp
Workspace table
- WorkspaceID
- UserID
- Shared
- Creation timestamp
File table
- FileID
- Filename
- UserID
- Path
- Type
- Checksum
- WorkspaceId
- File creation timestamp
- Last modified timestamp
- Latest version
File version table
- File version ID
- FileID
- DeviceID
- Version number
- Last modified timestamp
Block table
- BlockID
- File version ID
- Block index
Overall System
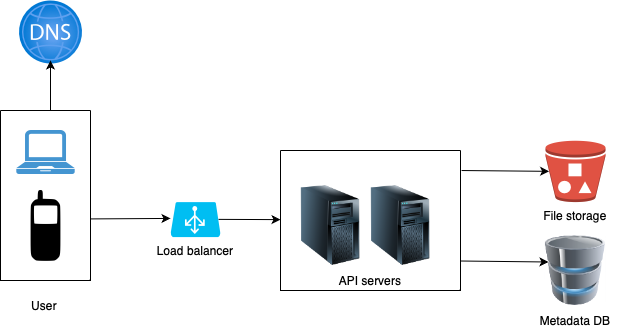
- Load Balancer: Evenly distributes network traffic. If a web server goes down, it will redistribute the traffic.
- API Servers: They handle upload and download requests. They can be added/removed easily, depending on the traffic load.
- File storage: Amazon S3 can be used for file storage. To ensure availability and durability, files are replicated in two separate geographical regions.
- Metadata database: Keeps track of metadata like user data, login info, files info, etc. Data replication and sharding can be set-up to meet the availability and scalability requirements.
Synchronisation conflicts
For a large storage system like Dropbox, synchronisation conflicts arise occasionally. A conflict occurs when two users modify the same file or folder simultaneously.
A simple strategy that we could use to resolve the conflict involves prioritising the first version that gets processed. The version that gets processed later receives a conflict.
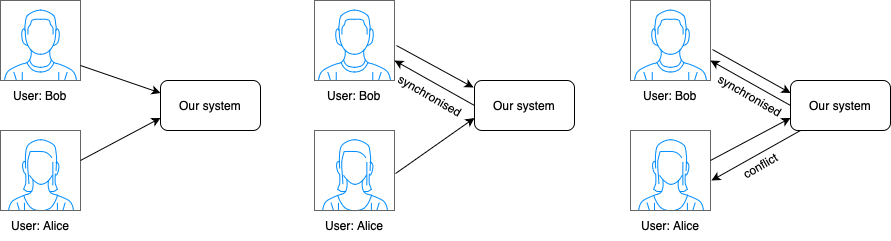
- User Bob and user Alice try to update the same file at the same time, but user Bob’s file is processed by our system first.
- User Bob’s update operation goes through, but, user Alice gets a sync conflict.
- Our system presents both copies of the same file to user Alice: user Alice’s local copy and the latest version from the server.
- User Alice has the option to merge both files or override one version with the other.
When multiple users are editing the same document at the same time, it is challenging to keep the document synchronised. Differential synchronisation offers scalability, fault-tolerance, and responsive collaborative editing across an unreliable network.
High-level Design
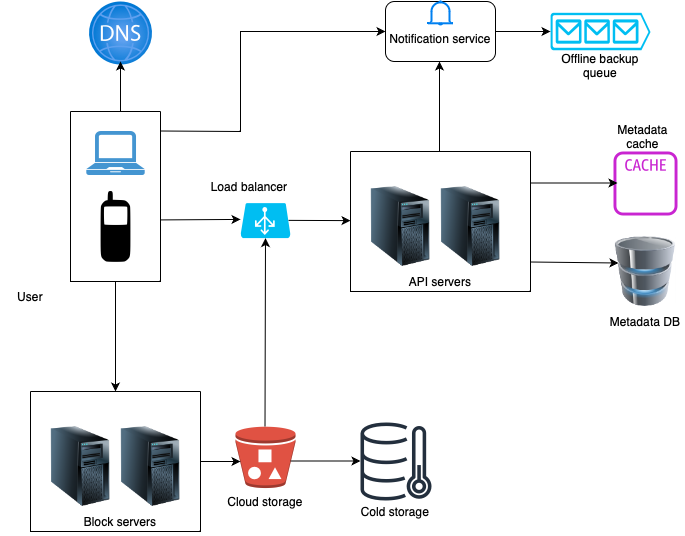
- User: A user uses the application either through a browser or mobile app.
- Block servers: Block servers upload blocks to cloud storage. A file can be split into several blocks (say of size 4 MB each), each with a unique hash value, stored in our metadata database. Each block is treated as an independent object and stored in our storage system (S3). To reconstruct a file, blocks are joined in a particular order.
- Cloud storage: A file is split into smaller blocks and stored in cloud storage.
- Cold storage: Cold storage is a computer system designed for storing inactive data, meaning files that have not been accessed for a long time.
- Load balancer: A load balancer evenly distributes requests among API servers.
- API servers: These are responsible for almost everything other than the uploading flow. API servers are used for user authentication, managing user profile, updating file metadata, etc.
- Metadata database: It stores metadata of users, files, blocks, versions, etc.
- Metadata cache: Some of the metadata are cached for fast retrieval.
- Notification service: It is a publisher/subscriber system that notifies relevant clients when a file is added/edited/removed elsewhere so they can pull the latest changes.
- Offline backup queue: If a client is offline and cannot pull the latest file changes, the offline backup queue stores this information so that changes will be synced when the client comes back online.
Deep Dive
Block Servers
In the case of large files that undergo frequent updates, transmitting the entire file with each update consumes a lot of bandwidth. To mitigate this, we need to minimise the volume of network traffic transmitted:
- Delta sync: When a file is modified, only the altered blocks are synchronised instead of the entire file, using a synchronisation algorithm.
- Compression: We can significantly reduce data size by applying compression on blocks, using compression algorithms depending on file types. Example:
- Text: Gzip, Bzip2, LZ77 and LZ78, etc.
- Images: JPEG, PNG, WebP, etc.
- Videos: H.264 (AVC), H.265 (HEVC), etc.
Block servers process files passed from clients by splitting a file into blocks, compressing each block, and encrypting them. Instead of uploading the whole file to the storage system, only modified blocks are transferred.
Adding a new file using block servers looks like the following.
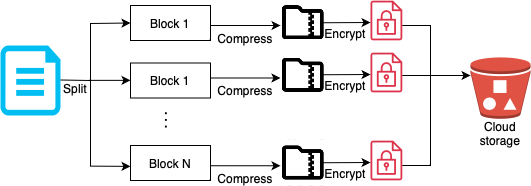
- A file is split into smaller blocks.
- Each block is compressed using compression algorithms.
- Every block is encrypted for security, before it is sent to cloud storage.
- Encrypted blocks are uploaded to the cloud storage.
Updating a file, only involves uploading the modified blocks as shown below.
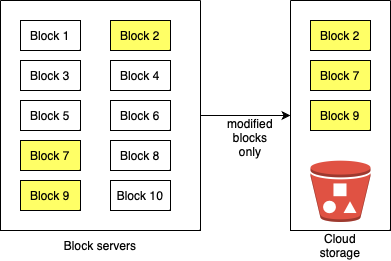
The above diagram shows how delta sync enables only modified blocks (block 2, 7 and 9 in this case) to be uploaded to the cloud storage.
High consistency
Consistency is very important in our system. It’s unacceptable to show the same file differently at different places at the same time.
Memory caches adopt an eventual consistency model by default, which means different replicas might have different data. To achieve strong consistency, we must ensure the following:
- Data in cache replicas and the primary cache is consistent.
- Invalidate caches on database write to ensure cache and database hold the same value.
Achieving strong consistency in a relational database is easy because it maintains the ACID (Atomicity, Consistency, Isolation, Durability) properties. However, NoSQL databases do not support ACID properties by default. ACID properties must be programmatically incorporated in synchronisation logic.
Let’s go with relational databases because the ACID is natively supported.
Upload flow
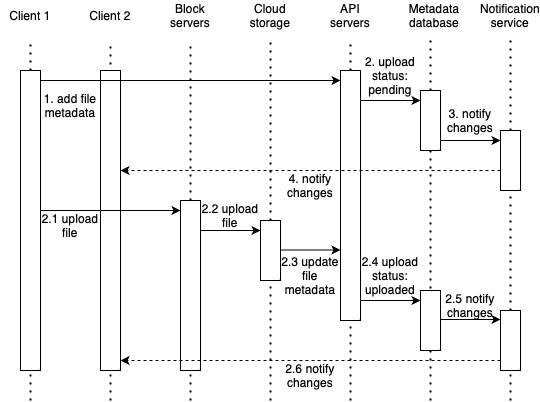
- When client 1 uploads a file, two requests are sent in parallel:
- Add file metadata
- Client 1 sends a request to add the new file metadata.
- The new file metadata is stored in metadata DB and the file upload status is changed to “pending”.
- Notification service gets notified about the new file being added.
-
The notification service notifies relevant clients (client 2) that a file is being uploaded.
- Add file metadata
-
- Upload the file to cloud storage
- 2.1 Client 1 uploads the content of the file to block servers.
- 2.2 Block servers chunk the files into blocks, compress, encrypt the blocks, and upload them to cloud storage.
- 2.3 Once the file is uploaded, cloud storage triggers upload completion callback. The request is sent to API servers.
- 2.4 File status is changed to “uploaded” in Metadata DB.
- 2.5 The notification service is notified that a file status has changed to “uploaded.”
- 2.6 The notification service notifies relevant clients (client 2) that a file has been fully uploaded.
- Upload the file to cloud storage
For editing a file, the flow is similar to this.
Download flow
Download flow is triggered when a file is added or edited elsewhere. There are two ways a client can know about a file being added or edited by another client:
- If client 2 is online while a file is being changed by another client (say client 1), notification service will inform client 2 that changes are being made elsewhere, prompting it to pull the latest data.
- If client 2 is offline while a file is being changed by another client, data will be saved to the cache. When the offline client becomes online again, it will pull the latest changes.
Once a client knows a file has changed, it first requests metadata via API servers, then downloads blocks to reconstruct the file.
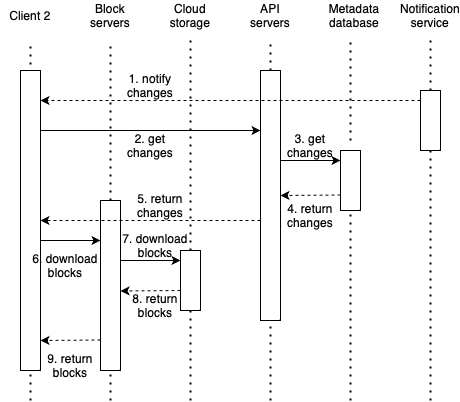
- Notification service informs client 2 that a file has been changed somewhere else.
- Once client 2 knows that new updates are available, it sends a request to fetch metadata.
- API servers call metadata DB to fetch metadata of the changes.
- Metadata is returned to the API servers.
- Client 2 gets the metadata.
- Once the client receives the metadata, it sends requests to block servers to download blocks.
- Block servers first download blocks from cloud storage.
- Cloud storage returns blocks to the block servers.
- Client 2 downloads all the new blocks to reconstruct the file.
Notification service
To maintain file consistency and reduce conflicts, any changes in a file performed locally needs to be conveyed to other clients. Notification service is built to serve this purpose. At the high-level, notification service allows data to be transferred to clients as events happen. Here are a few options:
- Long polling
- A variation of the traditional polling technique that allows the server to push information to a client, whenever the data is available.
- With long polling, the client requests information from the server exactly as in normal polling, but with the expectation that the server may not respond immediately.
- WebSocket
- WebSocket provides a persistent connection between the client and the server.
- Communication is bi-directional.
Let’s go with long polling for the following two reasons:
- Communication for notification service is not bi-directional. The server sends information about file changes to the client, but not vice versa.
- WebSocket is suited for real-time bi-directional communication such as a chat app. In Dropbox like system, notifications are sent infrequently with no burst of data.
With long polling, each client establishes a long poll connection to the notification service. If changes to a file are detected, the client will close the long poll connection. Closing the connection means a client must connect to the metadata server to download the latest changes. After a response is received or connection timeout is reached, a client immediately sends a new request to keep the connection open.
Storage Space
In order to maintain file version history and guarantee reliability, several copies of the same file are preserved in multiple data centres. However, frequent backups of all file revisions will take a lot of storage. To address this challenge and reduce storage expenses, we could try these:
- De-duplicate data blocks.
- We could try removing redundant blocks at user level, in a bid to save space. Two blocks are identical if they have the same hash value. We could use the following techniques:
- Post-process deduplication
- New blocks are first stored, and later some process analyses the data looking for duplication.
- Clients will not need to wait for the hash calculation or lookup to complete before storing the data, thereby ensuring that there is no degradation in storage performance.
- However, we will unnecessarily be storing duplicate data, though for a short time.
- Also, duplicate data will be transferred consuming bandwidth.
- In-line deduplication
- Hash calculations can be done in realtime as the clients are editing a file on their device. If our system identifies a block which it has already stored, only a reference to the existing block will be added in the metadata, rather than copying of the full block.
- This approach will give us optimal network and storage usage.
- Post-process deduplication
- We could try removing redundant blocks at user level, in a bid to save space. Two blocks are identical if they have the same hash value. We could use the following techniques:
- Moving infrequently used data to cold storage.
- Cold data is the data that has not been active for months or years. Cold storage like Amazon S3 glacier is much cheaper than S3.
- Intelligent data backup strategies.
- Version limit: We can limit for the number of versions to store. Beyond the limit, the oldest version will be replaced with the new version.
- Keep valuable versions only: Certain files may undergo frequent edits. For example, saving every edited version for a heavily modified document could mean the file is saved over 1000 times within a short period. To avoid unnecessary copies, we could limit the number of saved versions. We give more weight to recent versions. Experimentation is helpful to figure out the optimal number of versions to save.
Sharding
We can shard metadata DB in order to scale it, so that it can store information about millions of users and billions of files/blocks. Let’s look at the different sharding schemes:
- Vertical Sharding
- We can partition our database in such a way that we store tables related to one particular feature on one server.
- For example, we can store all the user related tables in one database and all files related tables in another database.
- This approach is simple and straightforward.
- However, there could be issues scaling this when one of the tables become very large.
- Joining two tables in two separate databases can cause performance and consistency issues.
- Range-based Sharding
- In this scheme, we store file/blocks in separate shards based on the first letter of their path. For example, all files with path name starting with ‘A’ are placed in shard A.
- This approach could lead to unbalanced servers.
- Hash-based Sharding
- In this approach, we can take a hash of the ‘FileID’ we are storing and based on this hash we figure out the DB partition to which this object should go.
- Our hashing function will randomly distribute objects into different shards.
- This could lead to overloaded shards, which could be solved by consistent hashing.
Caching
We can have caches at two places in our system: cache for block storage and cache for metadata DB.
- We can use an off-the-shelf solution like Memcached that can store frequently used blocks with their respective IDs/Hashes. Before hitting block storage, block servers can quickly check if the cache has the desired block.
- Based on clients’ usage pattern we can determine how many cache servers we need.
- When the cache is full, and we want to replace a chunk with a newer/hotter block, we could use Least Recently Used (LRU) cache eviction policy.
Similarly, we can have a cache for Metadata DB.
Load Balancer
- We can add load balancers at two places in our system:
- Between clients and block servers
- Between clients and API servers
- The load balancer would have a primary-secondary setup. If the primary load balancer goes down, secondary load balancer takes its place as the new primary, while we fix/replace the failing load balancer.
- We may start with a simple round robin approach that distributes incoming requests equally among backend servers. If a server is dead, LB will take it out of the rotation and will stop sending any traffic to it. This LB is simple to implement and does not introduce any overheads.
- A problem with round robin LB is that it doesn’t take server load into consideration. If a server is overloaded or slow, the LB will not stop sending new requests to that server.
- To handle this, a more intelligent LB solution can be placed that periodically queries backend servers about their load and adjusts traffic based on that.
Error Handling
Failures and errors are unavoidable in large-scale systems. We need to have error handling strategies in place to address them gracefully. Let’s look at some possible failures and how to handle them.
- Load balancer failure
- As mentioned above, we use a primary-secondary setup. If the primary load balancer fails, the secondary load balancer takes its place. In the mean time, the failing load balancer can be replaced or fixed.
- Block server failure
- In case a block server fails, other block servers can pick up the pending tasks instead.
- Cloud storage failure
- S3 buckets are replicated across geographic locations, so if the file is not available in one region, it can be accessed from some other region.
- API server failure
- If one API server fails, the load balancer can simply take that out of rotation and direct the traffic to the remaining servers.
- Metadata cache failure
- Metadata cache servers are replicated multiple times. If one node goes down, you can still access other nodes to fetch data. We will bring up a new cache server to replace the failed one.
- Metadata database failure
- Primary database down: If primary database server stops working, we could simply promote one of the secondary servers, and make it the new primary, while adding a new secondary node.
- Secondary database: Secondary database servers are used for read operations. If one of secondary servers is down, we could use the others for the time being and replace the failed server with a new one.
- Notification service failure
- Every online user keeps a long poll connection with the notification server. Thus, each notification server is connected with many users.
- If a server goes down, all the long poll connections are lost so clients must reconnect to a different server.
- Even though one server can keep many open connections, it cannot reconnect all the lost connections at once.
- Reconnecting with all the lost clients is a relatively slow process.
- Offline backup queue failure
- Queues are replicated multiple times. If one queue fails, consumers of the queue may need to re-subscribe to the backup queue.
Security
- Privacy and security are the two major concerns that users will have, while storing their files in the cloud.
- In our system, users can share their files with other users or even make them public to share it with everyone.
- A simple way to handle this is by storing permissions of each file in our metadata DB to reflect the file’s visibility and who can edit it.
- Visibility could be: global, authorised users, private.
- Editors could be: authorised users, self.
- Before a block can be accessed by a user, we check it’s visibility. If it is global, anyone can read the block. If it is authorised users, then the user trying to access the block needs to be in the list of authorised users to be able to read the block. Private means only the original author can read the block.
- If someone is trying to write to an existing block (edit a file), we’ll check if the user is either the original author, or an authorised user if editors is set to authorised users.