Problem Statement: Design a video sharing service like YouTube.
Clarifying Questions
- How many users do we expect?
- 100 million DAU (daily active users).
- How much time does a user spend on the platform on average?
- 30 minutes a day.
- Are we building everything from scratch, or can we use cloud services like CDN?
- Yeah, cloud services can be used in the design.
- Do we need to support mobile apps, web browsers and smart TVs?
- Yes.
- Is there any limit on the size of video, when uploading?
- Videos should be less than 10 GB in size.
- Can the user login at multiple places at a time?
- Yes.
- Do we support multiple languages?
- Let’s start with just English.
- Do we need to think about user signup, authentication, push notification, etc.?
- Let’s assume that these services are there.
- Do we support search history?
- No.
- Do we need encryption?
- Yes.
- Do we handle copyright issues, privacy violations, etc.?
- Let’s not worry about these at the moment.
Requirements
- Functional requirements
- Users should be able to upload videos fast.
- Users should be able to stream videos smoothly.
- Users should have the option to change video quality.
- User should be able to like/dislike the video, comment on it, see previous comments, number of likes/dislikes, number of comments, etc.
- Users could search videos based on their titles.
- Users may use mobile apps, web browser and smart TV.
- Non-functional requirements
- Low infrastructure cost.
- High availability; consistency can take a hit in favour of availability (if a user doesn’t see a video for some time, that’s fine).
- Highly scalable system, as the number of users are high and expected to grow.
- High reliability; uploaded videos shouldn’t be lost.
- User should have a smooth video play experience without any lag.
Back-of-the-envelope estimation
- Traffic
- Daily Active Users (DAU) = 100 million
- Let’s assume that a user watches 10 videos a day on average, so total videos viewed in a day = 1 billion
- Video views per second = 11500 (approx.)
- Let’s assume that 20% of users upload 1 video per day on average, so total videos uploaded in a day = 20 million
- Videos uploaded per second = 230 (approx.)
- Storage
- Let’s assume that on average, uploaded videos are 500 MB in size.
- Total Storage for 1 day = 20 million x 500 MB = 10 PB
- As, we need to store the videos forever, unless deleted by user, total storage for 10 years is approximately = 10 PB x 365 X 10 = 36.5 EB (Exabyte)
- Here, we only calculated the size of actual videos, and did not take into account video compression, replication, etc.
- Bandwidth
- We have approximately 11500 video views per second, and each video is assumed to be approximately 500 MB in size, so outgoing bandwidth = 5.75 TB/sec.
- And, we have approximately 230 video uploads per second, and each video is assumed to be approximately 500 MB in size, so incoming bandwidth = 115 GB/sec.
System APIs
upload_video(api_dev_key, title, description, category, languages, location, contents, tags)
- Arguments:
- api_dev_key (string): The API developer key of a registered account. This could be used to throttle users based on their allocated quota.
- title (string): Title of the video.
- description (string): Optional description of the video.
- category (string): Category of the video, e.g., Film, Song, People, etc.
- languages (string array): Languages used in the video.
- location (string): Location where the video is uploaded.
- contents (binary data): Video to be uploaded.
- tags: Optional tags for the video.
- Returns: (string)
- A successful upload will return HTTP 202 (request accepted), and once the video encoding is completed, the user is notified through email with a link to access the video.
search_video(api_dev_key, search_query, user_location, maximum_videos_to_return, page_token)
- Arguments:
- api_dev_key (string): The API developer key of a registered account of our service.
- search_query (string): A string containing the search terms.
- user_location (string): Optional location of the user performing the search.
- maximum_videos_to_return (number): Maximum number of results to be returned in one request.
- page_token (string): This token will specify a page in the result set that should be returned.
- Returns: (JSON)
- A JSON containing information about the list of video resources matching the search query. Each video resource will have a video title, a thumbnail, a video creation date and how many views it has.
Overall System
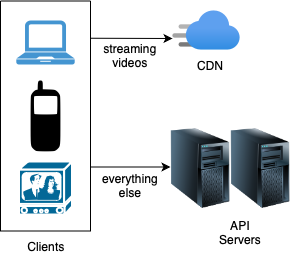
At a high-level, the three main components are:
- Client: Could be mobile apps, web browsers running on a computer or smart TVs.
- CDN: Videos are stored in and streamed from Content Delivery Network (CDN).
- API Servers: They handle everything except video streaming. This includes: user signup, authentication, feed recommendation, video encoder, video URL generator, etc.
Let’s look at the video uploading and streaming flows.
Video Uploading
Components
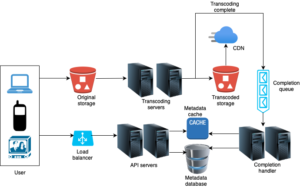
- User: A user watches or uploads a video on YouTube using a mobile app or browser on a computer or smart TV.
- Load balancer: A load balancer evenly distributes requests among API servers.
- API servers: All user requests go through API servers except video streaming.
- Metadata database: Video metadata and user information are stored in Metadata DB. It is sharded and replicated to meet performance and high availability requirements.
- Metadata cache: For better performance, video metadata and user objects are cached.
- Original storage: A blob storage system is used to store original videos.
- Transcoding servers: Video transcoding is also called video encoding. It is the process of converting a video format to other formats (MPEG, HLS, etc), which provide the best video streams possible for different devices and bandwidth capabilities.
- Transcoded storage: It is a blob storage that stores transcoded video files.
- CDN: Videos are cached in CDN. When you click the play button, a video is streamed from the CDN.
- Completion queue: It is a message queue that stores information about video transcoding completion events.
- Completion handler: This consists of a list of workers that pull event data from the completion queue and update metadata cache and database.
Uploading actual video
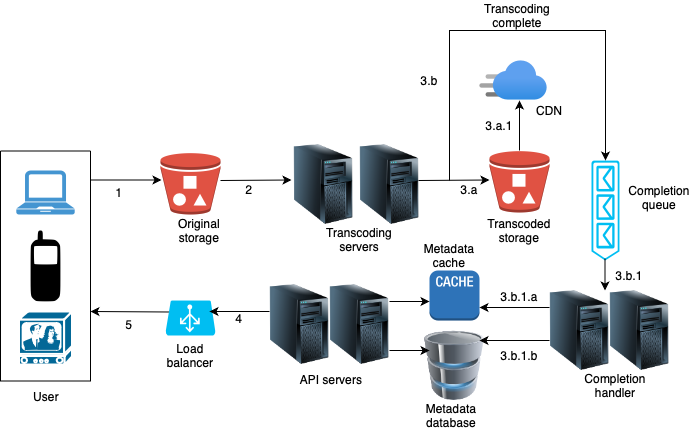
1. Videos are uploaded to the original storage.
2. Transcoding servers fetch videos from the original storage and start transcoding.
3. Once transcoding is complete, the following two steps are executed in parallel:
3.a. Transcoded videos are sent to transcoded storage.
3.a.1. Transcoded videos are distributed to CDN.
3.b. Transcoding completion events are queued in the completion queue.
3.b.1. Completion handler contains a bunch of workers that continuously pull event data from the queue.
3.b.1.a. and 3.b.1.b. Completion handler updates the metadata cache and database when video transcoding is complete.
4. API servers inform the client that the video is successfully uploaded and is ready for streaming.
Update metadata
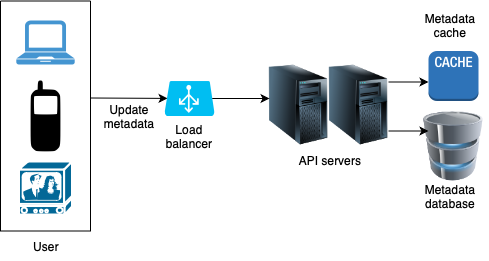
- While a file is being uploaded to the original storage, the client in parallel sends a request to update the video metadata as shown above.
- The request contains video metadata, including file name, size, format, etc.
- API servers update the metadata cache and database.
Video Streaming
When watching video, you don’t want the user to wait for the entire video to be downloaded before the user can start viewing it. We could instead stream videos, where the client loads a little bit of data at a time so users can watch videos immediately and continuously.
Streaming protocols provide a standard method to control data transfer for video streaming:
- HTTP Live Streaming (HLS)
- Real-Time Messaging Protocol (RTMP)
- Secure Reliable Transport (SRT)
- Dynamic Adaptive Streaming over HTTP (MPEG-DASH)
- Microsoft Smooth Streaming (MSS)
- Web Real-Time Communication (WebRTC)
Details of the protocol aren’t needed for an interview unless you work in this domain. The important thing here is to understand that different streaming protocols support different video encodings and playback players. When we design a video streaming service, we have to choose the right streaming protocol to support our use cases.
Videos are streamed from CDN directly. The edge server closest to you will deliver the video. Thus, there is very little latency.
Database
Video metadata can be stored in a SQL database.
- VideoID
- Title
- Description
- UserID
- Category
- Languages
- Location
- Tags
- Number of likes
- Number of dislikes
- Number of comments
- Number of views
- Thumbnail
- Timestamp
For each comment, we need to store the following:
- CommentID
- UserID
- VideoID
- Comment
- Timestamp
We could also store user information in a SQL database like MySQL.
- UserID
- Name
- Email id
- Location
- Age
- Gender
- Videos uploaded
- Account creation timestamp
- Last login timestamp
- Videos viewed per day
Deep Dive
Let’s refine both video uploading and streaming flows with important optimisations and add error handling mechanisms.
Video Transcoding
If you record a video on your phone, it stores the video file in a certain format. If you want the video to be played smoothly on other devices, the video must be encoded into compatible bitrates and formats, which is called video transcoding. Bitrate is the rate at which bits are processed over time. A higher bitrate generally means higher video quality. High bitrate streams need more processing power and fast internet speed.
Video transcoding is important for the following reasons:
- Raw videos take up large amounts of storage space.
- Many devices and browsers only support certain types of video formats.
- To ensure users watch high-quality videos while maintaining smooth playback, it is a good idea to deliver higher resolution video to users who have high network bandwidth and lower resolution video to users who have low bandwidth.
- Network conditions can change, especially on mobile devices. To ensure a video is played continuously, switching video quality automatically or manually based on network conditions is essential for smooth user experience.
Two important parts of a video coding format are:
- Container format: It is a file format that allows multiple data streams (audio, video, subtitles) to be embedded into a single file, usually along with some metadata. Example: AVI, MP4, FLV, etc.
- Codecs: These are compression and decompression algorithms that convert raw video data into a compressed format during encoding and decodes it back to its original form during playback. Some commonly used video codecs are H.264, H.265 (HEVC), H.266, VP9, AV1 and MPEG-2.
Directed Acyclic Graph (DAG) model
Video transcoding is a resource-intensive and time-consuming process. Furthermore, different content creators often have unique requirements for video processing. For instance, some creators may want to add watermarks to their videos, some prefer to provide their own thumbnail images, and some may upload high-definition videos while others do not.
To accommodate these diverse video processing needs and maintain efficient parallel processing, it becomes essential to introduce a level of abstraction that allows client programmers to specify which tasks to execute. For instance, Facebook’s streaming video engine employs a directed acyclic graph (DAG) programming model, organising tasks into stages for sequential or parallel execution. We can use a similar DAG model to provide flexibility and parallelism.
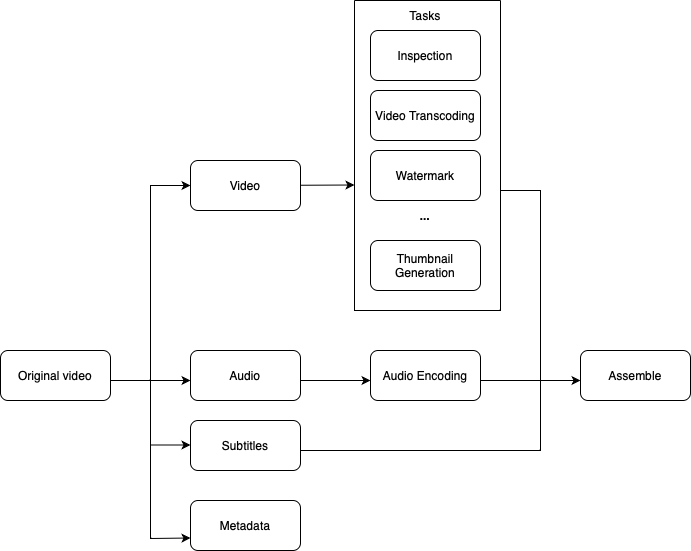
The original video is split into its three streams (video, audio, subtitles) and metadata. Some of the tasks applicable to the video stream are:
- Inspection: Verify that videos are good quality and not malformed.
- Video transcoding: Transform videos to accommodate various specifications, including resolutions, codecs, bitrates, etc.
- Watermark: An image overlay on top of your video contains identifying information about your video.
- Thumbnail generation: Thumbnails can either be user-uploaded or automatically generated by the system.
Video Transcoding Architecture
![]()
Let’s look at the main components:
- Preprocessor: It has the following responsibilities:
- Video splitting. Video stream is broken into segments consisting of a group of pictures (GOP). Segments split based on GOP alignment are, in essence, smaller stand alone videos.
- DAG generation. The preprocessor runs code associated with the uploading application to generate DAG. Dynamic generation of the DAG enables us to tailor a DAG to each video and provides a fexible way to tune performance and roll out new features. For instance, the DAG for a video uploaded at a low bitrate would not include tasks for re-encoding that video at a higher bitrate.
- Cache data. The preprocessor is a write-through cache for segments headed to storage. For better reliability, the preprocessor stores GOPs and metadata in temporary storage. If video encoding fails, the system could use persisted data for retry operations.
- DAG Scheduler
- The DAG scheduler splits a DAG graph into stages of tasks and puts them in the task queue in the resource manager.
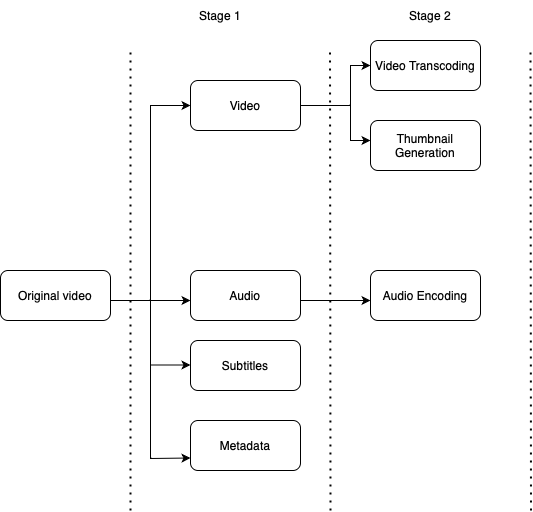
-
- As shown in the above picture, the original video is split into three stages: Stage 1: video, audio and metadata. The video file is further split into two tasks in stage 2: video encoding and thumbnail. The audio file requires audio encoding as part of the stage 2 tasks.
- Resource Manager
- The resource manager is responsible for managing the efficiency of resource allocation.
-
It contains 3 queues and a task scheduler as shown below:
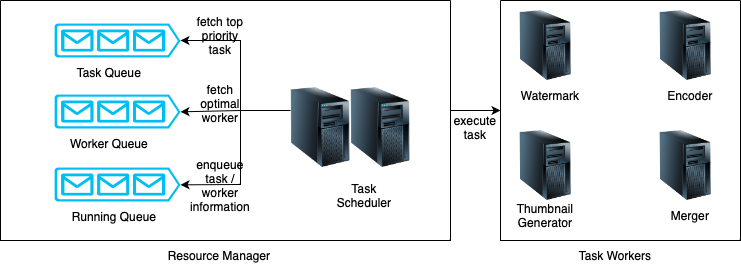
-
-
- Task queue: It is a priority queue that contains tasks to be executed.
- Worker queue: It is a priority queue that contains information about worker utilisation.
- Running queue: It contains information about the currently running tasks and workers running the tasks.
- Task scheduler: It picks the optimal task/worker, and instructs the chosen task worker to execute the job.
- The resource manager works as follows:
- The task scheduler gets the highest priority task from the task queue.
- The task scheduler gets the optimal task worker to run the task from the worker queue.
- The task scheduler instructs the chosen task worker to run the task.
- The task scheduler binds the task/worker info and puts it in the running queue.
- The task scheduler removes the job from the running queue once the job is done.
-
- Task Workers
- Task workers run the tasks which are defined in the DAG.
- Different task workers may run different tasks.
- Temporary Storage
- Multiple storage systems may be used here. The choice of storage system depends on factors like data type, data size, access frequency, data life span, etc.
- For instance, metadata is frequently accessed by workers, and the data size is usually small. Thus, caching metadata in memory is a good idea. For video or audio data, we put them in blob storage. Data in temporary storage is freed up once the corresponding video processing is complete.
- Encoded video
- This is the final output of the encoding pipeline.
System Optimisations
- Speed optimisation: parallel video uploading
- Uploading a video as a whole unit is inefficient. We can split a video into smaller chunks by GOP alignment.
- This allows fast resumable uploads when the previous upload failed. The job of splitting a video file by GOP can be implemented by the client to improve the upload speed.
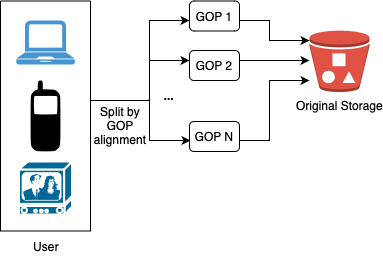
- Speed optimisation: user CDN
- Another way to improve the upload speed is by using CDN, so that people can upload the video in a nearby data centre.
- Speed optimisation: loose coupling, high parallelism
- Achieving low latency requires serious efforts. Another optimisation is to build a loosely coupled system and enable high parallelism.
- Our design needs some modifications to achieve high parallelism as every step depends on the previous output.
- We can use message queues to make the system loosely coupled, as shown below.
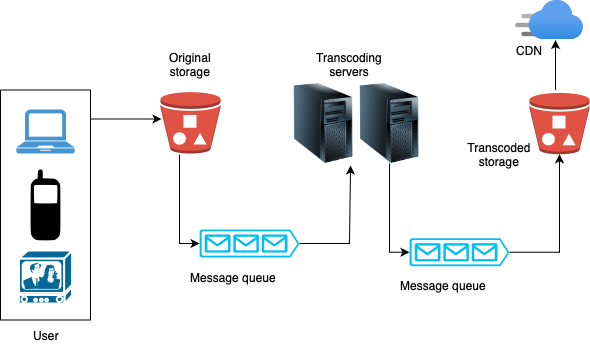
- Safety optimisation: pre-signed upload URL
- To ensure only authorised users upload videos to the right location, we can use pre-signed URLs.
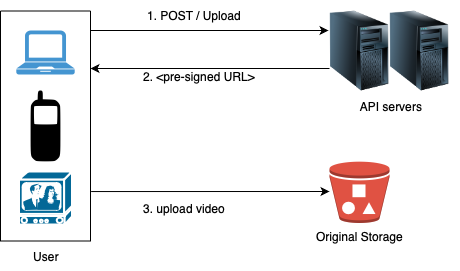
-
- The upload flow is updated as follows:
- The client makes an HTTP request to API servers to fetch the pre-signed URL, which gives access permission to the object identified in the URL.
- API servers respond with a pre-signed URL.
- Once the client receives the response, it uploads the video using the pre-signed URL.
- The upload flow is updated as follows:
- Safety optimisation: protect videos
- Many content makers are reluctant to post videos online because they fear their original videos will be stolen. To protect copyrighted videos, we can adopt one of the following three safety options:
- Digital rights management (DRM) systems: Three major DRM systems are Apple FairPlay, Google Widevine and Microsoft PlayReady.
- Advanced Encryption Standard (AES): You can encrypt a video and configure an authorisation policy. The encrypted video will be decrypted upon playback. This ensures that only authorised users can watch an encrypted video.
- Visual watermarking: This is an image overlay on top of your video that contains identifying information for your video. It can be your company logo or company name.
- Many content makers are reluctant to post videos online because they fear their original videos will be stolen. To protect copyrighted videos, we can adopt one of the following three safety options:
- Cost savings optimisation
- CDN is a crucial component of our system. It ensures fast video delivery on a global scale. However, it could be expensive.
- Previous research shows that YouTube video streams follow long-tail distribution. It means a few popular videos are accessed frequently but many others have few or no viewers. Based on this observation, we implement a few optimisations:
- Only serve the most popular videos from CDN and other videos from our high capacity storage video servers.
- For less popular content, we may not need to store many encoded video versions. Short videos can be encoded on-demand.
- Some videos are popular only in certain regions. There is no need to distribute these videos to other regions.
- We could build our own CDN like Netflix and partner with Internet Service Providers (ISPs). Building our own CDN is a giant project; however, this could make sense for large streaming companies. An ISP can be Comcast, AT&T, Verizon or other internet providers. ISPs are located all around the world and are close to users. By partnering with ISPs, we can improve the viewing experience and reduce the bandwidth charges.
All these optimisations are based on content popularity, user access pattern, video size, etc. It is important to analyse historical viewing patterns before doing these optimisation.
Video Deduplication
- With a large number of videos, there is a big possibilities of having duplicate videos. Storing multiple copies of the same video leads to wastage of storage.
- We could have a de-duplication service that runs when a user uploads a new video. The service could use block matching algorithm or Machine Learning based approaches to detect duplicates. If the video being uploaded is a duplicate, we could either notify the user, or just keep a copy of the video which is of higher quality.
Sharding
As we already mentioned earlier, the metadata database is sharded and replicated to meet high read and write load. We can use the following strategies to shard the databse:
- Sharding by UserID
- Here we consider storing all data related to a specific user on a single server. When storing data, we pass the UserID to our hash function, which directs us to the appropriate database server responsible for storing all metadata concerning that user’s videos.
- When querying for a user’s videos, we use our hash function to locate the server housing the user’s data and retrieve it from there.
- However, when searching for videos by titles, we’ll need to query all servers. Each server will return a set of videos, and a central server will then consolidate and rank these results before presenting them to the user.
- In the event that a user becomes exceptionally popular, the server housing that user’s data could experience a substantial surge in queries, potentially causing a performance bottleneck. This, in turn, may impact the overall performance of our service.
- Over time, certain users might accumulate a disproportionately large number of videos compared to others. Maintaining an equitable distribution of growing user data becomes quite complex.
- To address these scenarios, we must either redistribute our data partitions or employ consistent hashing to balance the workload among servers.
- Sharding by VideoID
- Our hash function assigns each VideoID to a random server where we store the corresponding video’s metadata.
- When searching for a user’s videos, we query all servers, and each server furnishes a collection of videos. Subsequently, a central server aggregates and ranks these results before delivering them to the user.
- This method resolves the issue of popular users but potentially shifts it to popular videos.
Error Handling
Errors are unavoidable for such a large-scale system. To build a highly fault-tolerant system, we must handle errors gracefully and recover from them fast. Two types of errors exist:
- Recoverable error: For recoverable errors such as video segment failing to transcode, the general idea is to retry the operation a few times. If the task continues to fail and the system believes it is not recoverable, it returns a proper error code to the client.
- Non-recoverable error: For non-recoverable errors such as malformed video format, the system stops the running tasks associated with the video and returns the proper error code to the client.
Typical errors for various system components and their workarounds are listed below:
- Upload error
- Retry a few times.
- Split video error
- If older versions of clients cannot split videos by GOP alignment, the entire video is passed to the server.
- The job of splitting videos is done on the server-side.
- Transcoding error
- Retry.
- Preprocessor error
- Regenerate DAG diagram.
- DAG scheduler error
- Reschedule a task.
- Resource manager queue down
- Use a replica.
- Task worker down
- Retry the task on a new worker.
- API server down
- API servers are stateless so requests will be directed to a different API server.
- Metadata cache server down
- Cached data is replicated multiple times.
- If one node goes down, we can still access other nodes to fetch data.
- We can bring up a new cache server to replace the dead one.
- Metadata DB server down:
- If the primary DB is down, we could promote one of the secondary DBs to act as the new primary DB.
- If a secondary DB goes down, we can use other secondary DBs for reads and bring up another database server to replace the dead one.