Problem Statement: Design a Machine Learning system like ChatGPT or Google Bard to generate human-like responses to queries.
Clarifying Questions
- What is the intended purpose or application of the chat system? Is it for customer support, virtual assistance, content generation, or another specific use case?
- This would help us understand the interviewer’s intent, and in making design decisions.
- Is there an existing system in place?
- If there is an existing system in place, then we have a baseline to compare our new ML system. Also, we may have some training data which could be used here.
- How many people are going to use the app?
- This would help us understand the scale.
- How will users interact with the chat system? Will it be through a text-based interface, voice-based interface, or a combination of both?
- It’s important to know the input and output format of our system.
- Are there any constraints or requirements on the user interface, such as limitations on message length, language, response time, or input formats?
- It’s vital to set the expectations on message length, ideal response time, etc. at the beginning and then build the system accordingly. Supporting multiple languages and input formats may make the system complicated, so you could start with just English and text input, and build a system that is easily extensible.
- Are there any specific user experience (UX) considerations, such as maintaining a conversational flow, understanding user intent, or providing context-aware responses?
- A ChatGPT like system should ideally provide context-aware responses, maintaining a conversational flow.
- Are there any restrictions or limitations on the data sources? Can we scrape web content or use existing datasets?
- For building such a generic system, you would probably need to scrape the entire web to get a wide variety of content to learn from. In addition, you could use some existing text datasets. It’s good to clarify these with the interviewer.
- Are there any considerations regarding data privacy, copyright, or user consent that need to be addressed during data collection?
- Asking these questions shows your awareness about the real-world problems that arise when working with external data.
- Where will the chat system be deployed? Is it intended for web-based platforms, mobile applications, or integrated into existing systems?
- It’s important to know the platforms we are intending to support for the new system. This would shape some of our decisions about model size, latency, response size, etc.
- Are there any specific safety or ethical considerations that should be taken into account? For example, detecting/ignoring/reporting biased or offensive responses, ensuring user privacy, or mitigating potential risks.
- When building a ChatGPT like system, which takes into consideration the current context and user responses, it’s crucial to have some safety mechanism and checks in place to be able to detect offensive/inappropriate user response and act accordingly.
Business Objective: The business objective could vary depending on the organisation. Example:
- Virtual assistants: Building virtual assistants powered by ChatGPT could be the intended purpose. These assistants can perform tasks such as scheduling appointments, managing calendars, providing reminders, or conducting basic research. The business object in this case could be user productivity improvement, user satisfaction.
- Personalised Recommendations and Assistance: ChatGPT can be leveraged to offer personalised recommendations and assistance to users. By understanding user preferences and context, the system can provide tailored suggestions, product recommendations, or assistance with complex tasks. This objective aims to enhance user experience, drive engagement, and increase conversion rates.
- Customer Support and Engagement: One common objective is to provide effective customer support and engagement. By deploying a chatbot powered by ChatGPT, businesses can automate responses to customer inquiries, provide instant support, and enhance the overall customer experience. The business metrics here could be customer satisfaction, retention rates and operational efficiency.
- Content Generation and Curation: Another objective is to use ChatGPT for content generation and curation purposes. The system can assist with creating blog posts, articles, social media content or other forms of content. It can help automate content creation, reduce the time and effort required and maintain a consistent tone and quality across various channels.
- Market Research and Insights: ChatGPT can be used to gather insights from user interactions and provide valuable data for market research. By analysing user queries, sentiment, and preferences, organisations can gain insights into customer needs, identify trends, and make data-driven decisions for product development, marketing strategies, or customer segmentation.
- Innovation and Research: Developing a system like ChatGPT can be driven by a desire to push the boundaries of artificial intelligence, natural language processing, and machine learning research. It can serve as a platform to explore new techniques, algorithms, or architectures, and advance the state of the art in language generation and understanding.
Requirements
- Training
- We are going to train a huge model which would take a lot of time and computational resources, and retraining from scratch would be very costly. So, we need to build a model which would work well on a variety of data, without the need to retrain it from scratch.
- Inference
- Real-Time Interaction: For a chat-based system, it is generally preferred to have low-latency responses to provide a smooth and interactive conversational experience. Users expect prompt responses, typically within a few seconds or less, to maintain the flow of the conversation and engage effectively.
- Scalability: The system’s ability to handle multiple user requests simultaneously and maintain consistent response times as the user load increases is crucial. Efficient resource allocation, parallel processing, and load balancing techniques can be employed to achieve scalability and ensure response time is not adversely affected by increased demand.
- Context and Conversation Length: In conversational systems, response time can be influenced by the length and complexity of the conversation history. Longer conversations may require more time for the model to process and generate a response. Strategies like truncation, summarisation, or hierarchical processing can be employed to manage response time while maintaining the context of the conversation.
Give an overview of the various components to discuss at this point: Training data, Feature Engineering, Modelling, Evaluation, Deployment and monitoring. Then proceed talking about each component. This shows organisation and structure to your approach, more typical of senior candidates.
Training Data
- How to collect training data?
- We need to collect a large diverse and representative dataset of conversations. We could use a web-crawler to gather a wide range of data including articles, books, websites along with publicly available text datasets from various domains.
- The data collection process would involve scraping and indexing publicly available text from the internet, which would then be used to train the language model. The web-crawling process is aimed to capture a broad representation of human knowledge and language patterns to make the model more versatile and capable of generating coherent responses on a wide range of topics.
- We could also use human annotators to create and annotate training data, although this would be expensive and time-consuming.
- We could also leverage the common crawl dataset. This is a large enough dataset (near a trillion words) sufficient to train really large models.
- Data Quality:
- Ensuring data reliability and quality is a significant challenge. We could improve the data quality of the common crawl dataset by applying deduplication techniques to filter out duplicates and adding known high-quality corpora (like Wikipedia) to increase its diversity.
- The web contains vast amounts of information, including noisy, inaccurate, controversial or biased content, which can unintentionally influence the model’s behaviour. Filtering out irrelevant or low-quality data while maintaining a diverse and representative dataset requires careful curation and preprocessing. Efforts need to be made to identify and mitigate biases in the training data to ensure the resulting model is fair, unbiased, and respectful of diverse perspectives. We should favour trusted sources, reputable websites, academic publications, and curated datasets, while avoiding sources known for inaccurate or biased information.
- We should apply preprocessing techniques to filter out irrelevant or low-quality data, removing duplicates, spam, advertisements, and other noise from the dataset using heuristics, regular expressions, or machine learning methods to identify and remove noisy or irrelevant content. Human reviewers can help verify the quality, correctness, and relevance of the collected data.
- We need to establish quality control mechanisms to evaluate the performance and behaviour of the trained model. We should continually monitor the outputs, collect user feedback, and iteratively refine the model and data collection process based on the feedback received. Continuously updating and expanding the dataset to include new and relevant information is crucial. We need to regularly assess the effectiveness of data cleaning and filtering methods and refine them as needed.
- We could establish guidelines and protocols to handle offensive or inappropriate content encountered during data collection.
- Data Privacy:
- Collecting data from the web raises privacy and legal concerns. Care must be taken to respect copyright laws, terms of service of websites and user privacy. To ensure user privacy and data protection, we may anonymise/remove personal information from the data.
- Scalability:
- Training a large language model like ChatGPT requires significant computational resources, including powerful hardware and storage capacity. Ensuring scalability and efficient processing of the collected data can be a challenge.
- Data Contamination:
- When using datasets such as the common crawl, it can potentially include content from test datasets simply because such content often exists on the web. We may need ways to measure data contamination and quantify its distorting effects.
Feature Engineering
- The training data consists of text, so we need ways to featurise text into feature vectors. Before featurisation, we may need to perform the following pre-processing steps:
- Tokenisation
- This involves breaking down the text into smaller units called tokens. Tokens can be words, subwords or characters, depending on the tokenisation strategy.
- Common tokenisation methods include word tokenisation, subword tokenisation (e.g., Byte-Pair Encoding – BPE), and character tokenisation. For example, the sentence “BERT used to be very popular.” might be tokenised into [“BERT”, “used”, “to”, ” be”, “very”, “popular”, “.”].
- Lowercasing
- Lowercasing helps in ensuring consistency and treating identical words (with different cases) as the same, reducing the vocabulary size and simplifying the learning task for the model.
- Removing punctuation and special characters
- Punctuation and special characters might not always carry meaningful information and could be removed to focus on the essential content.
- Handling numerical values
- We may be need to decide how to handle numerical values, whether to keep them as-is, replace them with a placeholder, or convert them to text.
- Stopword removal
- Removing common words (stopwords) that do not contribute much to the meaning of a sentence, can reduce noise and decrease the dimensionality of the feature space.
- Handling contractions and abbreviations
- This may help ensure that the model understands the full meaning of words.
- Spelling correction
- Correcting misspellings would likely improve the model’s ability to understand and generate text correctly.
- Handing rare or out-of-vocabulary words
- Rare words might not have sufficient occurrences for the model to learn meaningful representations.
- One way to handle them would be to replace them with a special token.
- Stemming and lemmatisation
- Reducing words to their root form (stemming) or base dictionary form (lemmatisation), can help in capturing the core meaning of words.
- Example of stemming: going -> go
- Example of lemmatisation: better -> good
- Handling emoticons
- It might be a tricky to decide whether to keep or remove emojis as they might carry important sentiment or contextual information.
- Tokenisation
- After pre-processing, we could generate word embeddings and positional encodings which can be fed to the model for training.
- Word Embeddings: Word embeddings are a fundamental feature in language models. They represent words as dense numerical vectors in a continuous space, capturing semantic and syntactic relationships between words. These embeddings allow the model to understand and reason about the meaning of words in the context of a given sentence or document.
- Positional Encodings: Positional encodings are used to convey the relative positions of words in a sequence. Since language models process text sequentially, positional encodings provide the model with information about the order of words in a sentence, enabling it to understand the sequential nature of language.
Modelling
- Transfer Learning:
- We could start by using transfer learning with GPT (Generative Pre-trained Transformer) and BERT (Bidirectional Encoder Representations from Transformers) models. These models are pre-trained on large corpora and then fine-tuned for specific downstream tasks, enabling them to capture general language understanding and context. This would enable us to quickly have a baseline model without needing much training data. However, performance would be a limitation for this model.
- Language Models with External Knowledge:
- Some large language models incorporate external knowledge sources to enhance their understanding and generation capabilities. For example, models like KnowBERT or ERNIE (Enhanced Representation through Knowledge Integration) integrate knowledge graphs or external knowledge bases to improve language understanding and reasoning. This would usually improve on the performance of transfer learning approaches.
- Recurrent Neural Networks (RNNs):
- Recurrent Neural Networks, particularly variants like Long Short-Term Memory (LSTM) or Gated Recurrent Unit (GRU), are used for language modelling. They are sequential models processing one token at a time, which limits their computational efficiency (can’t parallelise training). They suffer from vanishing gradient problem, which causes issue with long sequence of text.
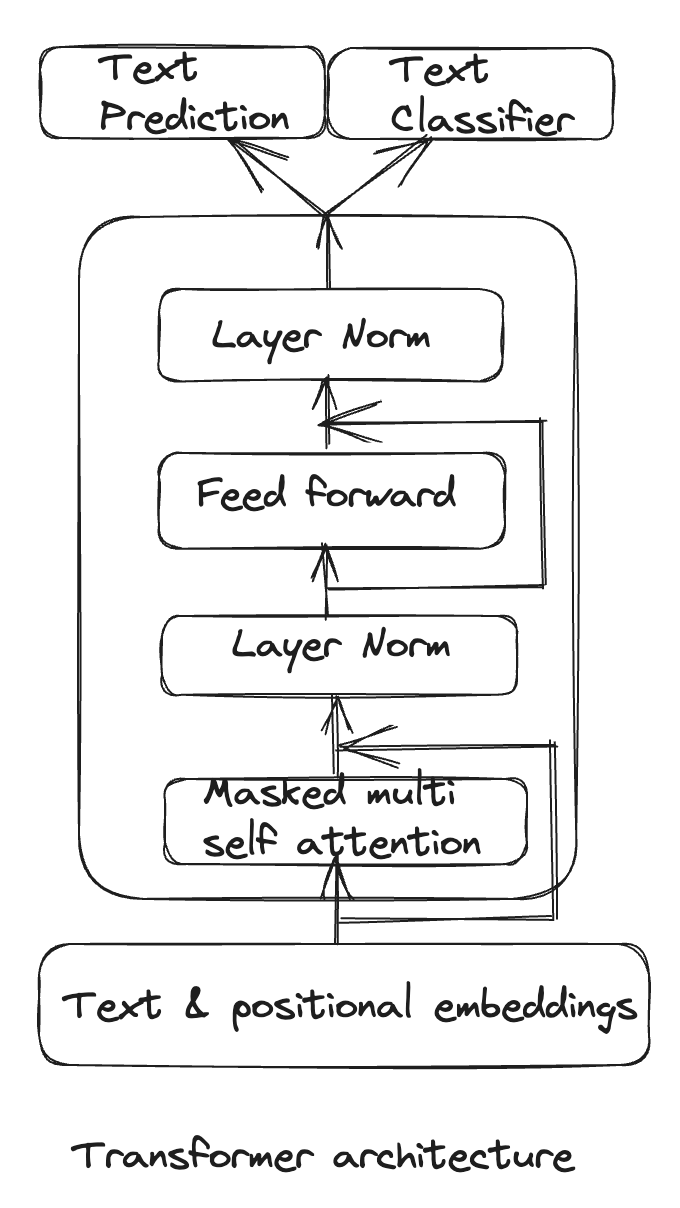
- Transformer-based Models:
- Transformer architecture has been extensively used in large language modelling.
- Here, the training procedure consists of two stages. The first stage is learning a high-capacity language model on a large corpus of text. This is followed by a fine-tuning stage, where we adapt the model to a discriminative task with labelled data.
- Unsupervised pre-training
- Given a large corpus of tokens
 , we may use a standard language modelling objective to maximise the following likelihood:
, we may use a standard language modelling objective to maximise the following likelihood:
 , where k is the size of the context window, and the conditional probability P is modelled using a neural network with parameters
, where k is the size of the context window, and the conditional probability P is modelled using a neural network with parameters  . These parameters can be trained using stochastic gradient descent.
. These parameters can be trained using stochastic gradient descent.
- We can use a multi-layer Transformer decoder for the language model. This model applies a multi-headed self-attention operation over the input context tokens followed by position-wise feedforward layers to produce an output distribution over target tokens:

 transformer_block
transformer_block![(h_{l-1}) \forall i \in [1, n]](https://eliterate.me/wp-content/ql-cache/quicklatex.com-9e1f9eb0f9a34309700a11502632b9a6_l3.png "Rendered by QuickLaTeX.com")
 softmax
softmax
- where
 is the context vector of tokens, n is the number of layers,
is the context vector of tokens, n is the number of layers,  is the token embedding matrix, and
is the token embedding matrix, and  is the position embedding matrix.
is the position embedding matrix.
- Given a large corpus of tokens
- Supervised fine-tuning
- After training the model with the objective mentioned above, we can adapt the parameters to the supervised target task. Assuming a labelled dataset C (discussed next), where each instance consists of a sequence of input tokens,
 , along with a label y. The inputs are passed through our pre-trained model to obtain the final transformer block’s activation
, along with a label y. The inputs are passed through our pre-trained model to obtain the final transformer block’s activation  , which is then fed into an added linear output layer with parameters
, which is then fed into an added linear output layer with parameters  to predict y:
to predict y:
 softmax
softmax
- Objective to maximise:
- We could also add language modelling as an auxiliary objective to fine tuning:

- This may improve generalisation of the supervised model and accelerate convergence.
- After training the model with the objective mentioned above, we can adapt the parameters to the supervised target task. Assuming a labelled dataset C (discussed next), where each instance consists of a sequence of input tokens,
- Input transformation
- In our system, we would need to task-specific labelled dataset. This could be obtained using some heuristic on data or human annotators, depending on the task.
- For example, for customer support, we may have historical chats with end-users which could be used. Responses to user queries could be used as labels. There could be multiple possible labels in this scenario.
- So, given a context document z, a question q, and a set of possible answers {
 }, we concatenate the document and question with each possible answer, adding a delimiter token in between to get: [
}, we concatenate the document and question with each possible answer, adding a delimiter token in between to get: [ ].
]. - Each of these sequences are processed independently with our model and then normalised via a softmax layer to produce an output distribution over possible answers.
- Unsupervised pre-training

![]()
-
- Alternatives to fine-tuning:
- Few-shot:
- The model is given a few demonstrations of the task at inference time as conditioning, but no weight updates are allowed. Few-shot works by giving K examples of context and completion, and then one final example of context, with the model expected to provide the completion.
- The main advantages of few-shot are a major reduction in the need for task-specific data and reduced potential to learn an overly narrow distribution from a large but narrow fine-tuning dataset.
- The main disadvantage is that results from this method are usually worse than state-of-the-art fine-tuned models. Also, a small amount of task specific data is still required.
- One-shot
- Same as few-shot except that only one demonstration is allowed, in addition to a natural language description of the task.
- The reason to distinguish one-shot from few-shot and zero-shot (below) is that it most closely matches the way in which some tasks are communicated to humans.
- Zero-shot
- Same as one-shot except that no demonstrations are allowed, and the model is only given a natural language instruction describing the task.
- This method provides maximum convenience, potential for robustness, and avoidance of spurious correlations (unless they occur very broadly across the large corpus of pre-training data), but is also the most challenging setting.
- In some cases it may even be difficult for humans to understand the format of the task without prior examples, so this setting is in some cases “unfairly hard”.
- Few-shot:
- To prevent such a large model running out of memory while training, we could use model parallelism.
- Alternatives to fine-tuning:
Evaluation and Deployment
- For few-short learning, we can evaluate each example in the evaluation set by randomly drawing K examples from the task’s training set as conditioning.
- On tasks like customer support that involve choosing one correct completion from several options (multiple choice), we could provide K examples of context plus correct completion, followed by one example of context only, and compare the LM (Language Model) likelihood of each completion.
- On tasks with free-form completion like content generation, we can use beam search. We can score the model using F1 similarity score, BLEU, or exact match, depending on the dataset at hand.
- Evaluation Metrics:
- Offline metrics:
- Perplexity: Perplexity is a widely used metric for language modelling tasks. It measures how well a language model predicts a given sequence of words. Lower perplexity indicates better performance, as it signifies that the model can more accurately predict the next word in a sequence.
- BLEU (Bilingual Evaluation Understudy): BLEU is a metric commonly used to evaluate the quality of machine-generated text. It measures the similarity between generated text and reference text by comparing n-grams (contiguous sequences of words) in both texts. Higher BLEU scores indicate better similarity with the reference text.
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation): ROUGE is a set of metrics used to evaluate the quality of machine-generated summaries. It measures the overlap between generated summaries and reference summaries in terms of n-gram matches and sentence-level overlaps. Higher ROUGE scores indicate better summarisation performance.
- F1 Score: The F1 score is a commonly used metric for evaluating the performance of models in tasks like question answering. It considers both precision (accuracy of positive predictions) and recall (ability to find all positive instances) to provide a balanced measure of performance.
- Online metrics:
- Human Evaluation: In addition to automated metrics, human evaluation is crucial to assess the quality of generated responses. Human evaluators can rate the relevance, coherence, fluency, and overall quality of the generated text. This subjective evaluation provides valuable insights into the user experience and helps identify areas for improvement.
- User Engagement Metrics: In the context of chat systems, metrics related to user engagement can be relevant. These may include metrics such as user satisfaction ratings, average session duration, user retention rates, or conversion rates. These metrics can provide insights into the system’s ability to engage and satisfy users.
- Choice of metrics depends on the specific objectives and use cases of the system. Different metrics may be more appropriate for different scenarios. It’s often beneficial to use a combination of automated metrics, human evaluation and user engagement metrics to obtain a comprehensive understanding of the system’s performance.
- Offline metrics:
- Once the model is trained and fine-tuned, we can deploy it to a production environment where it can interact with users. We could run A/B tests to validate and check the new model’s performance.
- We should continuously monitor the performance of our system in the production environment and collect feedback from users. We need to regularly iterate on the model to improve its performance, address any issues, and adapt to changing user needs.
- When designing a chat system like ChatGPT, it’s crucial to consider ethical aspects. We need to ensure that the system is designed to prevent biased or harmful outputs, handle sensitive information appropriately, and prioritise user safety and privacy. This could done using a heuristic or ML-model that does the final check before the response is send to the user. Also, users should be able to report inappropriate responses and these feedbacks should be handled with high priority.