Problem Statement: Design an ML system to recommend videos to a user in a video serving application (similar to YouTube).
Clarifying Questions
- Is there an existing system in place?
- If there is an existing system in place, then we have a baseline to compare our new ML system.
- Do we have subscriptions? Are we focussing on just personalised recommendations or do we consider contents based on subscriptions as well?
- To start with we could just focus on personalised recommendations. Once this system has been built, we could add recommended content from user’s subscriptions.
- How many users are going to use this application?
- This would help us understand the scale that we are dealing with.
- Do we have data about user preferences (or user profile)?
- This is a very important information needed to build our ML system. Most probably the interviewer will tell you that you have some data on user preferences available to be used. If not, you could suggest using the existing system (if there is one in use) to log user data for a month. If the system doesn’t exist, we could build a naive system to rank videos based on popularity to create one big “trending” page and show it to everyone.
- How many videos do we have?
- Again, this would help us understand the scale of the system.
- Are people constantly uploading new videos?
- We may want to keep retraining our model based on the frequency and scale of new videos being uploaded.
- What kind of information about videos do we have in the database?
- We would need metadata, language, author information, video quality, encoding, etc. about the videos. Subtitles, if available, may be helpful.
- Are all users logged in while using the app?
- The question is about personalised recommendations, so we would need user history for that, which means users need to be logged in. If a user isn’t logged in, we could fall back to a generic “trending page” or show trending videos based on location.
- Is this a global app? Do we support multiple languages?
- If we are building a global app, we would eventually need to support multiple languages. We could start with supporting videos in English language and then extend support to other languages.
Business Objective
- Improve user engagement/user satisfaction or ad revenue (the better the video, the more people will be willing to see the ad before the video).
- User satisfaction could be a combination of clicks, watch time, likes, dislikes, shares and survey responses.
Requirements
- Training
- User preferences may change regularly and new videos may become popular. So we need to train our model regularly. We could start with training daily and change it to multiple times a day if the improvements in metrics justify the extra infrastructure costs.
- Inference
- For every user to visit the homepage, the system will have to recommend 100 videos for them. The latency needs to be under 500ms.
- For video recommendations, it’s important to find the right balance between exploration vs exploitation. If the model over-exploits historical data, new videos might not get exposed to users. We want to balance between relevancy and new videos.
Give an overview of the various components to discuss at this point: Training data, Feature Engineering, Modelling, Evaluation, Deployment and monitoring. Then proceed talking about each component. This shows organisation and structure to your approach, more typical of senior candidates.
Training Data
- How to collect training data?
- Training data would consist of videos, user information and historical interactions between users and videos. We could collect user information from their profile which they setup when signing up for the app. Videos can be uploaded by signed in users. We could ask users to fill in some details about the video like caption, category, language, etc. and infer other details like video length, quality, etc.
- We could fix the number of training examples per user.
- Labelling
- We could use user interactions for labelling the videos.
- Explicit signals: Like, comment, reshare, survey responses could be used to label the videos. However, this would be very sparse and not scale well.
- Implicit signals: Watch time could be used for labelling. A watch time greater than some threshold (like 80% of the video length) could be treated as positive. Similarly, if a user quickly closes the video, that’s clearly a negative example, effectively weighting our users equally in the loss function. This would prevent a small cohort of highly active users from dominating the loss.
- ML task
- We could start with a model that optimises watch time. We could add other ML tasks like optimising clicks, likes, comments, etc. and combine (weighted linear combination) the scores from different models to get a final score to be used for recommendation. These weight coefficients could be adjusted based on business requirements. Training data for likes, comments would be less compared to watch time as only a fraction of people like or comment on videos.
- Feedback loops in using logged data
- Focussing on watch time to start with gives a higher volume of user feedback to train and evaluate your model.
- We need to be aware of degenerate feedback loops, which can happen when the predictions themselves influence the feedback, which, in turn, influences the next iteration of the model. For example, in the initial iteration, say videos A and B are very close in terms of their scores but because A was originally ranked a bit higher, it showed up higher in the recommendation list, making users click on or view A more, which made the system rank A even higher. After a while, A’s ranking became much higher than B’s. This can cause the model to perform sub-optimally, perpetuate and magnify biases present in the data.
- To address this problem, we could use two techniques: randomisation and using positional features.
- Mixing random items with system recommended items helps reduce homogeneity and improve diversity.
- To use positional features to combat degenerate feedback loops, we can use two different models. The first model predicts the probability that the user will see and consider a recommendation taking into account the position at which that recommendation will be shown. The second model then predicts the probability that the user will click on the item given that they saw and considered it. The second model doesn’t concern positions at all.
- Class Imbalance
- We are using watch time to classify instances. Positive samples (watch time > some threshold like 80%) would be a lot less than negative samples (impressions), leading to class imbalance. This could cause problems if the data is highly imbalanced and there aren’t enough signals to learn the minority class.
- If class imbalance is deemed a problem after analysing the data, we could use resampling (oversampling the minority class or undersampling the majority class), but this could have its own issues like risk of losing important data after undersampling and risk of overfitting after oversampling.
- We could also use algorithmic methods to deal with this (for details, see Training Data).
- Ensembles seem to work well when there is class imbalance.
- Cold-start problem
- We would encounter this when we have no historical data for the model to use. This would happen when a new user signs up or a new video gets uploaded.
- One way to solve this problem is using representative approach. For a new user, we could show some contents on sign-up and deduce interest based on clicks or explicitly ask user to like or dislike some videos.
- Similarly, for videos we could find similar videos and use that or boost newly added videos in recommendations.
Feature Engineering
- Features:
- User only
- gender, age, location, demographics, metadata, user_interests, user_historical_views, user_historical_likes, user_historical_dislikes, user_historical_comments, known_languages, user_historical_searches, device, user_last_search_query, is_logged_in, user_language, average_watch_time_percent
- Video only
- author, length, video_language, topic/category, number_of_ratings, clicks, clicks_in_last_24_hours, clicks_in_last_7_days, uploaded_time (age_of_video), impressions, impressions_in_last_24_hours, impressions_in_last_7_days, likes_count, comments_count, comments, average_watch_time_percent_in_last_24_hours, average_watch_time_percent_in_last_7_days
- age_of_video
- We expect many hours worth of videos getting uploaded each second to YouTube. Recommending this recently uploaded (“fresh”) content is extremely important for YouTube as a product as users usually prefer fresh relevant content.
- Machine learning systems often exhibit an implicit bias towards the past because they are trained to predict future behaviour from historical examples.
- To correct for this, we could feed the age of the video (by subtracting uploaded_time from current_time) as a feature during training. At serving time, this feature would be set to zero to reflect that the model is making predictions at the very end of the training window.
- User-author interaction features
- number_of_author_videos_viewed, number_of_author_videos_liked, number_of_author_videos_disliked, number_of_author_videos_commented, average_watch_time_percent_author_videos
- User-video interaction features
- time_since_last_impression, has_viewed, has_liked, has_disliked, has_commented, number_of_watches_on_same_topic
- Context features
- time_of_the_day, day_of_the_week, season_of_the_year, is_holiday_season, month, upcoming_holidays, days_to_upcoming_holiday
- User only
- Feature types and featurisation techniques:
- Numeric features
- For numeric features like age, clicks, likes_count, comments_count, days_to_upcoming_holiday, etc., first we would want to look at missing values and handle them.
- If a feature has too many missing values, we could consider removing the column. However, this might remove some important information and reduce the accuracy of the model.
- Also, if a sample has missing values, we could remove that row. This method can work when the missing values are completely at random and the number of examples with missing values is small.
- Even though deletion is tempting because it’s easy to do, deleting data can lead to losing important information and introduce biases into the model. We could fill missing values with default value or using mean, median or mode.
- It’s important to scale the features before inputting it into a model. We could do min-max scaling (normalisation): x’ = (x – min(x)) / (max(x) – min(x)), which would output the values in the range: [0, 1]. Standardisation is another option which would make the values have zero mean and unit variance: x’ = (x – mean(x)) / std(x).
- Categorical features
- For categorical features like month, season_of_the_year, etc., we could use One Hot Encoding. This would lead to complex computation and high memory usage for categories with high cardinality, if we are building a large scale system. Also, new categories may appear in production, and marking all of them into one category (others) may not be optimal.
- We could use the hashing trick to encode categorical features, by using a hash function to generate a hashed value of each category. The hashed value will become the index of that category. Because we can specify the hash space, we can fix the number of encoded values for a feature in advance, without having to know how many categories there will be, enabling new categories to appear in production without any issues.
- Collision is a problem with hash functions, especially in cases of small hash size. We can increase the hash size, but that will consume more memory. With hash function, the collisions are random and the impact of collided features isn’t bad in most cases.
- Embeddings
- We can generate embeddings for user and video features as explained later.
- We can generate text embeddings for textual features like metadata, comments, etc. using pre-trained models like word2vec, GloVe, etc. (We could also briefly mention bag of words and TF-IDF vectoriser, listings its disadvantages).
- Numeric features
Modelling
- If there is no baseline recommendation system, we could have a system rank videos based on popularity to create one big “trending” page. However, this kind of system would be irrelevant to lots of people as everyone has unique viewing habits.
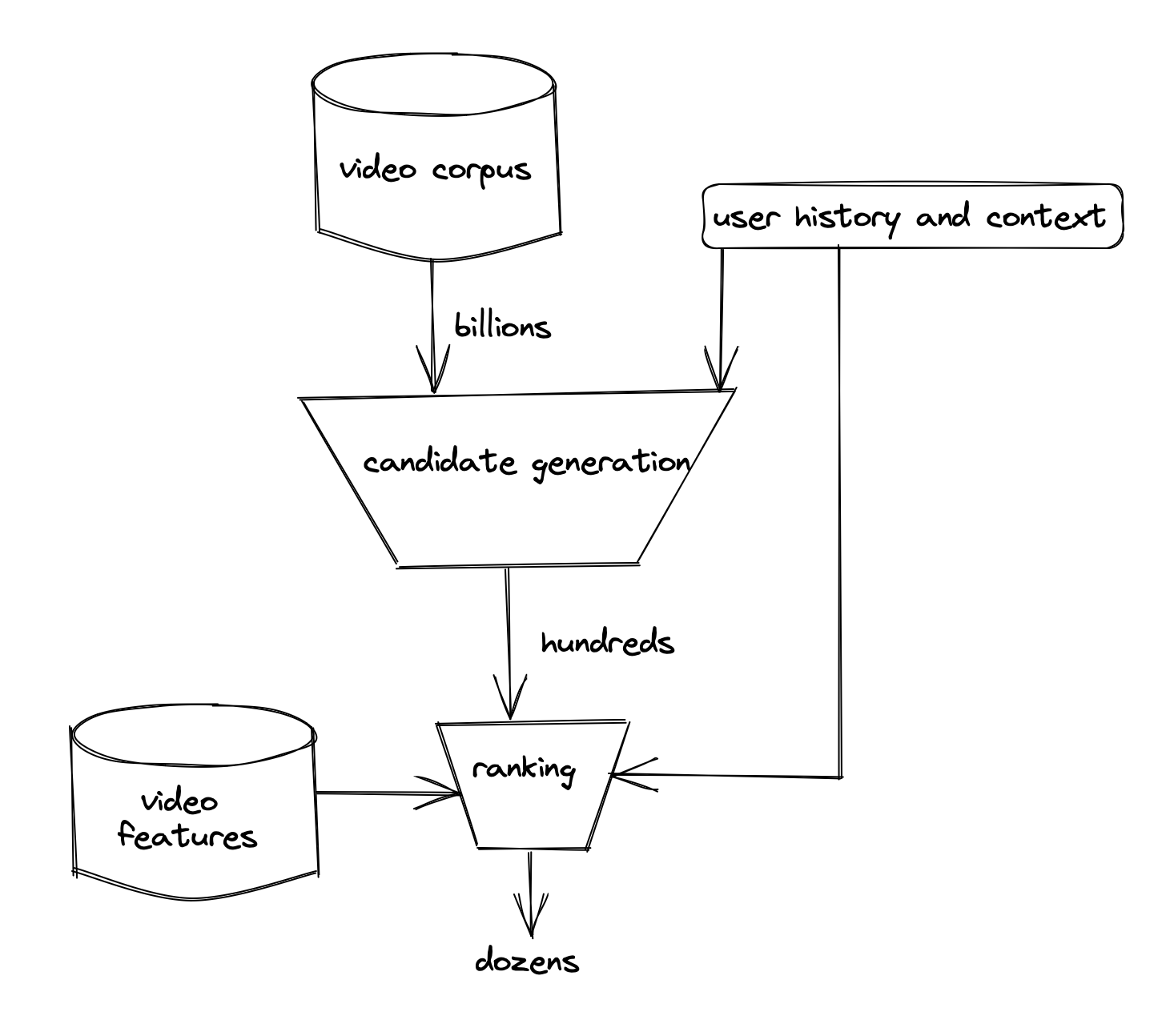
- The system is comprised of two neural networks: one for candidate generation and one for ranking.
- The candidate generation network takes events from the user’s YouTube activity history as input and retrieves a small subset (hundreds) of videos from a large corpus. These candidates are intended to be generally relevant to the user with high precision. The candidate generation network only provides broad personalisation.
- Presenting a few “best” recommendations in a list requires a fine-level representation to distinguish relative importance among candidates with high recall. The ranking network accomplishes this task by assigning a score to each video according to a desired objective function using a rich set of features describing the video and user.
- The two-stage approach to recommendation allows us to make recommendations from a very large corpus (millions) of videos while still being certain that the small number of videos appearing on the device are personalised and engaging for the user. Furthermore, this design enables blending candidates generated by other sources.
Overall system:
Candidate generation:
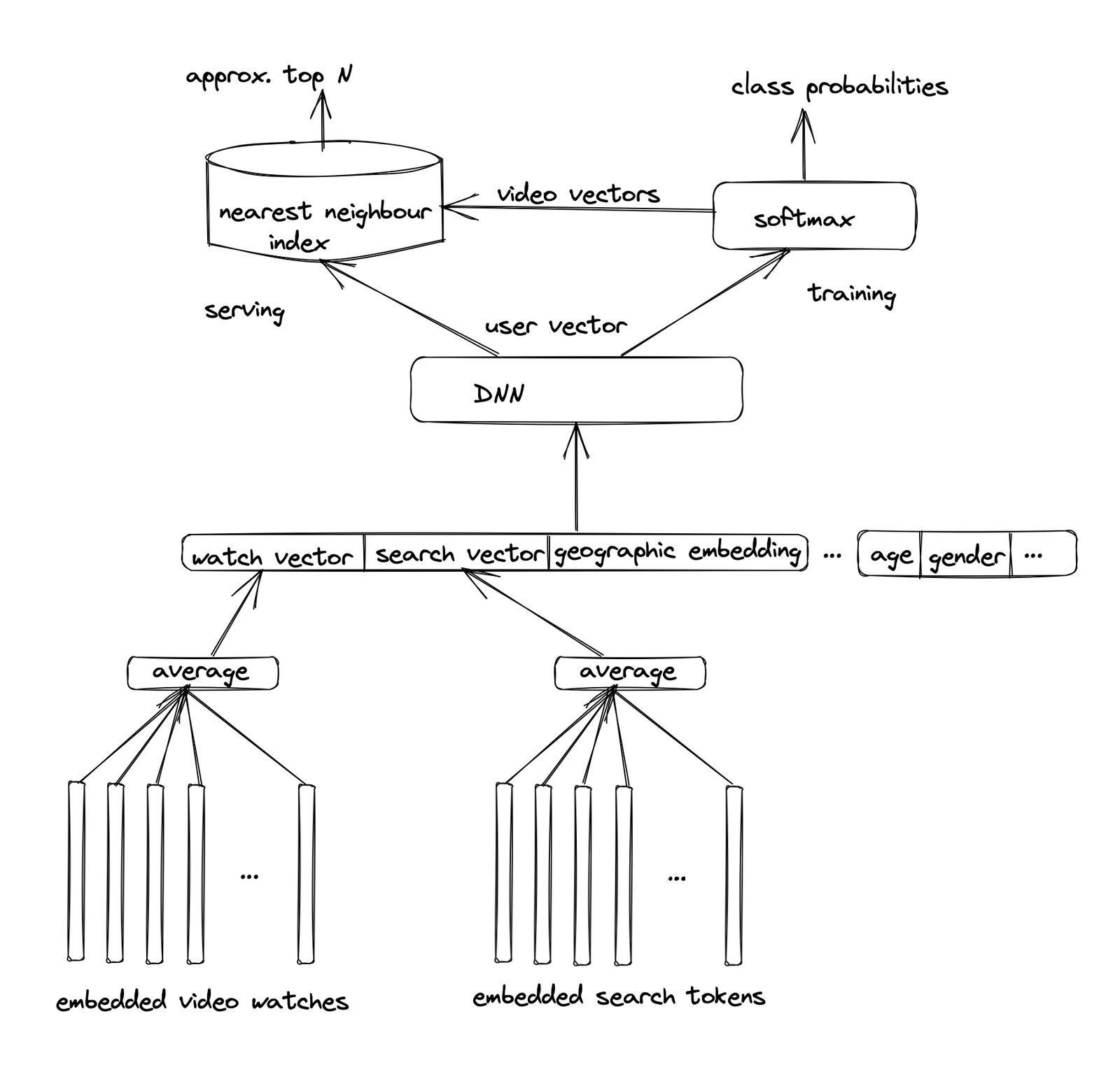
- During candidate generation, the enormous video corpus is distilled down to hundreds of videos that may be relevant to the user.
- Video watches refer to the videos that users watched, and search tokens are tokenised search history of the user. Embeddings for these are high-dimensional, with millions of learnable parameters. They can be learnt jointly with the entire network via backpropagation.
- Feed-forward networks require fixed size inputs. Number of watches and search tokens can vary dramatically between users. So, we need to summarise these into fixed size inputs. We could perform average, or summation, or component-wise max operation, since we don’t lose much information in high dimension.
- Concatenating other features like age, gender, etc. is easy in this setup.
- DNN could be comprised of fully-connected layers with ReLU activation.
- The final layer of the DNN would give user embeddings.
- For training, we could pose the problem as extreme multi-class classification where the prediction problem becomes accurately classifying a specific video watch
 at time t among millions of videos i (classes) from a corpus V based on a user U and context C.
at time t among millions of videos i (classes) from a corpus V based on a user U and context C.  , where
, where  represents a high-dimensional “embedding” of the user, context pair and
represents a high-dimensional “embedding” of the user, context pair and  represent embeddings of each candidate video.
represent embeddings of each candidate video.- Here, an embedding is simply a mapping of sparse entities (individual videos, users etc.) into a dense vector in
 . The task of the deep neural network is to learn user embeddings u as a function of the user’s history and context that are useful for discriminating among videos with a softmax classifier.
. The task of the deep neural network is to learn user embeddings u as a function of the user’s history and context that are useful for discriminating among videos with a softmax classifier. - To efficiently train such a model with millions of classes, we can use a technique to sample negative classes from the background distribution (“candidate sampling”) and then correct for this sampling via importance weighting.
- At serving time we need to compute the most likely N classes (videos) in order to choose the top N to present to the user. Scoring millions of items under a strict serving latency requires an approximate scoring scheme sub-linear in the number of classes.
- Since calibrated likelihoods from the softmax output layer are not needed at serving time, the scoring problem reduces to a nearest neighbour search in the dot product space.
You could also briefly talk about matrix factorisation (a type of collaborative filtering algorithm) and mention its advantages and disadvantages here.
Ranking:
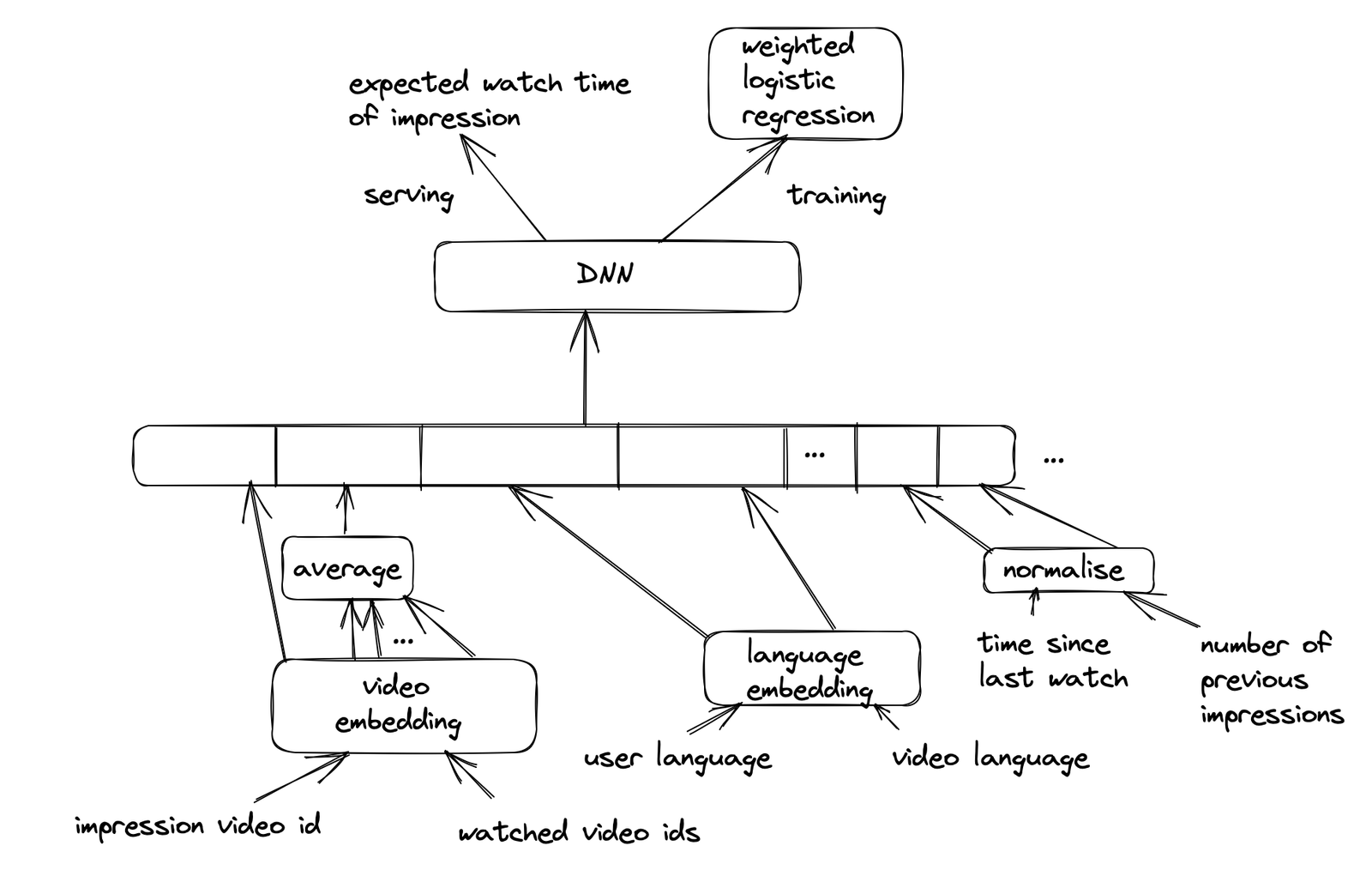
- The primary role of ranking is to use impression data to specialise and calibrate candidate predictions for the particular user interface. For example, a user may watch a given video with high probability generally but is unlikely to click on the specific homepage impression due to the video title.
- During ranking, we have access to many more features describing the video and the user’s relationship to the video because only a few hundred videos are being scored rather than the millions scored in candidate generation.
- We use a deep neural network with multiple fully-connected layers with ReLU activation function (similar architecture as candidate generation) to assign an independent score to each video impression using logistic regression. The list of videos is then sorted by this score and returned to the user.
Evaluation and Deployment
Evaluation metrics
- Offline Metrics:
- MAP@k (Mean Average Precision)
- It gives insight into how relevant the list of recommended items are.
- Precision, P = Number of relevant recommendations / total number of recommendations
 , where
, where  if
if  item is relevant else
item is relevant else  ,
,  = precision for top i recommendations, m = total number of relevant recommendations.
= precision for top i recommendations, m = total number of relevant recommendations.- MAP@k = Mean of AP@k
- MAR@k (Mean Average Recall)
- It gives insight into how well the recommender is able to recall all the items the user has rated positively.
- Recall = Number of relevant recommendations / Number of all possible relevant items
 , where if item is relevant else ,
, where if item is relevant else ,  = recall for top i recommendations, m = total number of relevant recommendations.
= recall for top i recommendations, m = total number of relevant recommendations.- MAR@k = Mean of AR@k
- MAP@k (Mean Average Precision)
- Online Metrics:
- Click-through rate (CTR), Watch time, User Engagement
- These could be directly tied back to the business objective.
- Setup train, test, validate partitions (to prevent overfitting)
- We could split the 30-day training data we have into training, validation and test set. Sequence is important here, so we could use the first 20 days of data for training, next 5 days for validation and the last 5 days for testing.
- If we decided to resample the training data to handle class imbalance, we should not evaluate our model on resampled data, since it will cause the model to overfit to that resampled distribution.
- A/B test setup
- We could use the existing model as control group and the new model as test group.
- In a big company, many people may be running A/B experiments with their candidate models. It’s important to make sure your results are not getting affected by other experiments. It’s good to create multiple universes consisting of external users where all experiments corresponding to a particular feature/project are run in the same universe. Inside a universe, an external user can only be assigned to one experiment, thus making sure multiple experiments from the same universe won’t influence each other’s results.
- After doing sanity check for any config errors, we route half the traffic to control group and wait for a week before analysing the results.
- We could use chi-squared test or two-sample test to see if the results are statistically significant and decide whether the new model improves on the previous model.
- Debugging offline/online metric movement inconsistencies
- It’s important to continuously monitor the ML system and have health checks in place and alerts enabled.
- We should ideally have dashboards showing the important metrics (both business and performance) and changes in these metrics over time.
- If these metrics go below a certain threshold, we should have an alerting system in place to notify the correct team.
- We should also have logging in place, which would help with debugging these issues.
- A common cause of drop in model performance is data distribution shift, when the distribution of data the model runs inference on changes compared to the distribution of data the model was trained on, leading to less accurate models.
- We could work around the problem of data distribution shift either by training the model on a massive training dataset with the intent that the model learns a comprehensive distribution, or by retraining the model (from scratch or fine-tuning) to align with the new distribution.
- Edge cases can also make the model make catastrophic mistakes and need to be kept in mind when debugging.