Problem Statement: Design a photo-sharing service like Instagram, where users can upload photos and share them with other users.
Clarifying Questions
- How many users do we expect?
- 500 million DAU (daily active users).
- How much time does a user spend on the platform on average?
- 30 minutes a day.
- Are we building a mobile app or a web app?
- Both.
- Can the user login at multiple places at a time?
- Yes.
- Do we support multiple languages?
- Let’s start with just English.
- Do we need to think about user signup, authentication, push notification, etc.?
- Let’s assume that these services are there.
- Do we support search history?
- No.
- Do we need to support videos as well?
- No.
- Do we handle copyright issues, privacy violations, etc.?
- Let’s not worry about these at the moment.
- Do we need to support photo tagging?
- No.
- Do users have the ability to report posts or mute a user?
- This isn’t a priority. We could add this at the end, time permitting.
Requirements
- Functional requirements
- Users should be able to upload photos through posts which can contain one or more photos and some text.
- Users should be able to view posts.
- Users should be able to like the photos and add comments.
- Users should be able to share the post.
- Users should be able to follow other users.
- Users should be able to view a newsfeed consisting of posts from people they follow.
- Non-functional requirements
- The service should be highly available.
- The service should be highly reliable; once a user uploads a photo, it should never get lost (unless the user deletes the photo manually).
- Once the user logs in or opens the app, the user should be able to view the newsfeed in under a second.
- Consistency can take a hit, in favour of availability (if a user doesn’t see a post for some time, that should be fine).
Back-of-the-envelope estimation
- Traffic
- Daily Active Users (DAU) = 500 million
- Let’s assume that 1 in 5 users uploads an image per day on average, so total images uploaded in a day = 100 million
- Images uploaded per second = 1160 (approx.)
- Storage
- Let’s assume that on average, uploaded images are 2 MB in size.
- Total storage required for 1 day = 100 million x 2 MB = 200 TB
- As we need to store the images forever (unless deleted by the user), total storage required for 10 years is approximately = 200 TB x 365 X 10 = 730 PB (Petabyte)
- Here, we only calculated the size of actual images, and did not take into account image compression, replication, post text data, other metadata, etc.
System APIs
post_upload(auth_token, user_id, image_data[], text_data, location, timestamp)
- auth_token: Used for authenticating API requests
- user_id: current user id.
- image_data[]: one or more images to be uploaded
- text_data: text associated with the image(s).
- location: current user location
- timestamp: time at which the post was shared by the user.
- returns a bool indicating success or failure of the operation
newsfeed_retrieve(auth_token, user_id, timestamp)
- auth_token: Used for authenticating API requests
- user_id: current user id.
- timestamp: time when user opened the app.
- returns newsfeed on success; error code/message on failure.
Overall System
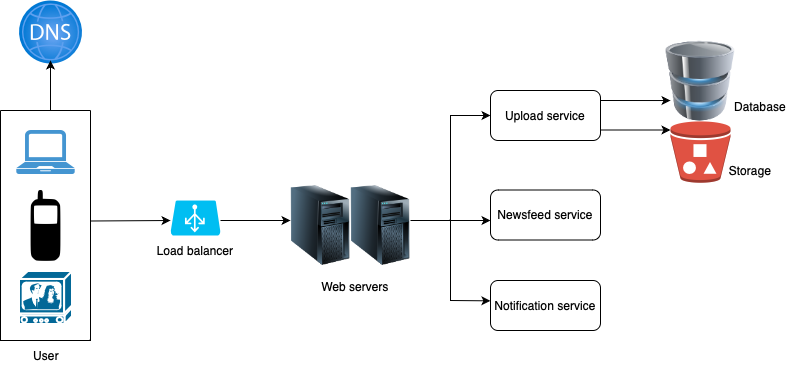
There are two main components in our system: upload service and newsfeed service.
- Upload service: When a user uploads a photo (in a post which may contain some text as well), upload service is called into action. It saves the photo in the storage and associated metadata in the database.
- Newsfeed service: When a user opens the mobile app or the web app, newsfeed service populates the user’s screen with posts/photos from other users that the current user follows.
Database
A post can contain some text and multiple images. A post table will have the following attributes:
- PostID
- UserID
- Text
- ImageIDs
- Timestamp
- Location
Image metadata will have the following attributes.
- ImageID
- UserID
- Path
- Location
- Number of likes
- Number of dislikes
- Number of comments
- Number of views
- Timestamp
For each comment, we need to store the following:
- CommentID
- UserID
- ImageID
- Comment
- Timestamp
We could also store user information.
- UserID
- Name
- Email id
- Location
- Date of birth
- Gender
- Images uploaded
- Account creation timestamp
- Last login timestamp
- Time spent on platform per day
We also need a UserFollow table.
- UserID1
- UserID2
We could use relational database like MySQL to store the above, since we require joins. But relational databases come with their challenges, especially when we need to scale them. Let’s calculate the capacity needed to store the user post data in the database (excluding the user data; this doesn’t consider actual images which will be stored in separate storage).
- Total size for 1 day = number of posts * (post table size + image metadata table size) + number of comments * comment table size = 100 million * (240 bytes + 140 bytes) + 1 billion * 120 bytes (Assuming each post has 10 comments on average) = 158 GB.
- Total size for 1 year = 148 GB x 365 = 58 TB (approx.)
We can leverage the distributed key-value store to capitalise on the advantages provided by NoSQL. Specifically, all image metadata can be organised within a table where the ‘key’ corresponds to the ‘ImageID,’ and the ‘value’ comprises of an object containing the other attributes mentioned above. Similarly, we could hand post, comment and user tables.
Additionally, we must establish and manage relationships between users, posts and photos to determine photo ownership. Another set of relationships involves tracking the individuals a user follows and comments on posts. For these relational data requirements, a wide-column data store like Cassandra or a graph database like Neo4J can be used. Graph databases are well-suited for managing friend relationships.
Actual photos can be stored in a distributed file storage like HDFS or S3. For faster retrieval (given that this will be a global application), we could consider using a CDN.
Deep Dive
Posting a photo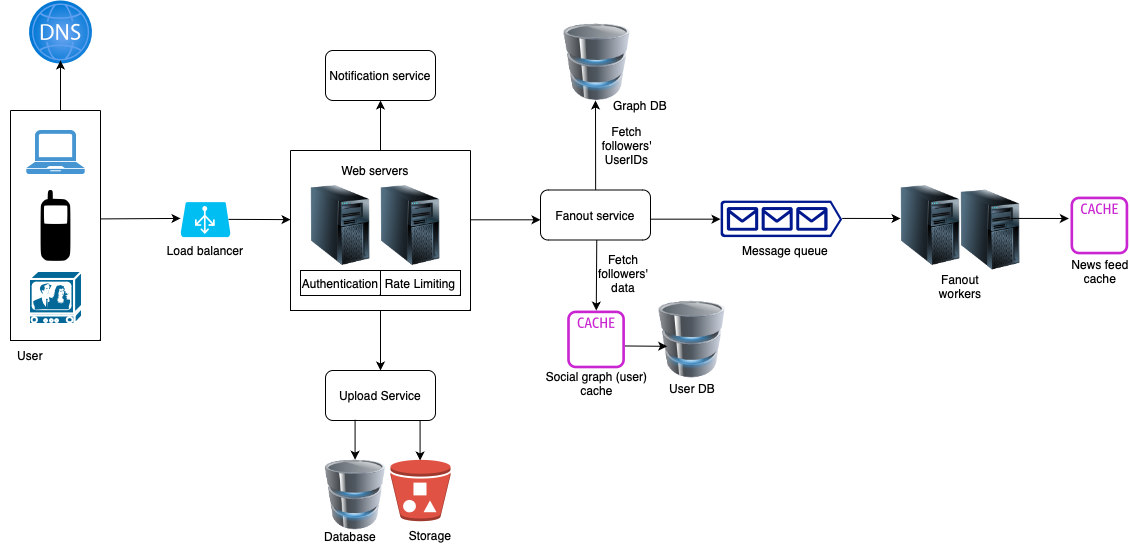
- When a user publishes a new post, the client connects to the Load Balancer (after getting the IP address from DNS). The load balancer distributes traffic between various web servers.
- Web servers enforce authentication and rate-limiting.
- Only signed-in users with valid auth_token are allowed to publish their posts. The system limits the number of posts a user can make within a certain interval, to prevent spam and misuse.
- The upload service then stores the photo in the storage and associated metadata in the database. We would want replication in place for reliability.
- Once we publish the post, it’s important that the post reaches its intended audience (most likely the user’s followers). Fanout deals with the process of delivering a post to all of user’s followers.
- Two types of fanout models are:
- Push model (fanout on write)
- With this approach, news feed is pre-computed during write time. A new post is delivered to followers’ cache immediately after it is published.
- Advantages:
- The news feed is generated in real-time and can be pushed to followers immediately.
- Fetching news feed is fast because the news feed is pre-computed during write time.
- Disadvantages:
- If a user has many followers, fetching the list of followers and generating news feeds for all of them will be slow and time consuming (hotkey problem).
- For inactive users or those who rarely log in, pre-computing news feeds waste computing resources.
- Pull model (fanout on read)
- The news feed is generated during read time. This is an on-demand model. Recent posts are pulled when a user loads the home page.
- Advantages:
- For inactive users or those who rarely log in, fanout on read works better because it will not waste computing resources on them.
- Data is not pushed to followers so there is no hotkey problem.
- Disadvantages:
- Fetching the news feed is slow as the news feed is not pre-computed.
- Hybrid approach
- We could use the push model for most of our users, as fetching the news feed fast is crucial.
- For celebrities or users who have many followers, we can let the followers pull news content on-demand to avoid system overload.
- Consistent hashing is a useful technique to mitigate the hotkey problem as it helps to distribute requests/data evenly.
- Push model (fanout on write)
The fanout service works as follows:
- Fetch userIDs of all the user’s followers from the graph database.
- Get followers’ info from the user cache. The system then filters out followers based on user settings. For example, if you mute someone, that user’s posts will not show up on your news feed even though you still follow that user. Another reason why posts may not show is that a user could selectively share information with specific people or hide it from other people.
- Send followers’ list and new postID to the message queue.
- Fanout workers fetch data from the message queue and store news feed data in the news feed cache. You can think of the news feed cache as a <post_id, user_id> mapping table. Whenever a new post is made, it will be appended to the news feed table. The memory consumption can become very large if we store the entire user and post objects in the cache. Thus, only IDs are stored. To keep the memory size small, we can set a configurable limit. The chance of a user scrolling through thousands of posts in news feed is slim. Most users are only interested in the latest content, so the cache miss rate would be low.
- Store <post_id, user_id> in news feed cache.
News feed retrieval
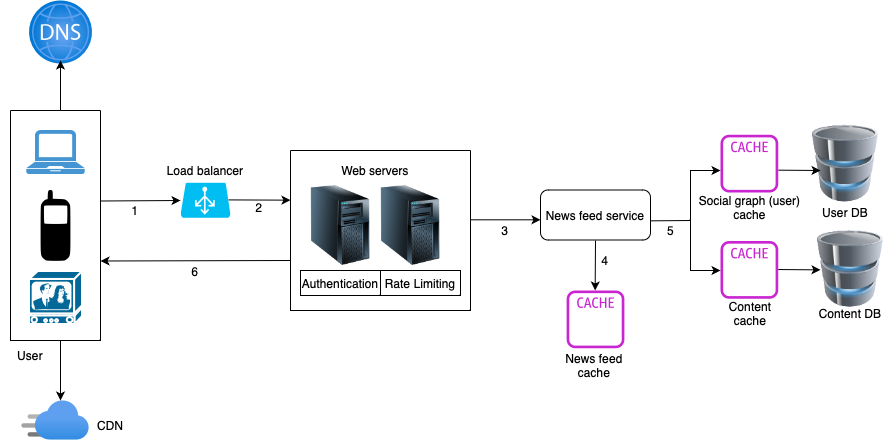
- A user sends a request to retrieve the news feed.
- The load balancer redistributes requests to web servers.
- Web servers call the news feed service to fetch the news feed.
- News feed service gets a list of postIDs from the news feed cache.
- A user’s news feed is more than just a list of postIDs. It contains username, profile picture, post images, text data, date and time of the post, location, etc. Thus, the news feed service fetches the complete user and post objects from caches (social graph cache and content cache) to construct the fully hydrated news feed.
- The fully hydrated news feed is returned in JSON format back to the client for rendering.
Feed ranking service
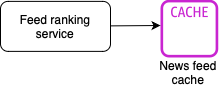
Feed ranking service keeps updating the news feed in the news feed cache. We can try different approaches for ranking the news feed:
- Reverse chronological order: This is one of the simplest heuristics we can try. It would show the most recent posts on top.
- Trending posts on top: We can calculate the trending metric of different posts as a combination of number of likes, comments, shares, views, etc. and use this metric to sort the posts.
- Machine Learning: It would be ideal to use ML to rank the news feed. Most companies today do that. Check “Facebook news feed” for more details.
In the end, it’s important to keep monitoring the metrics (like ad revenue, user satisfaction, user retention, time spent on platform, user engagement, etc.) that’s important to us and adapt our ranking service accordingly.
Cache Architecture
Cache plays a vital role within the news feed system. We segment the cache into five layers:
- News Feed: It stores IDs of news feeds.
- Content: It stores post data. Popular content is stored in hot cache.
- Social Graph: It stores user relationship data along with user details.
- Action: It stores information about whether a user liked a post, commented on a post, or took other actions on a post.
- Counters: It stores counters for like, comment, follower, following, etc.
- Sharding by UserID
- Let’s assume we shard based on the UserID so that we can keep all photos of a user on the same shard.
- If one DB shard is 7.3 TB, we will need 730 PB / 7.3 TB = 100,000 shards for storing 10 years worth of data.
- We can find the shard number by UserID % 100,000 and then store the data there. To uniquely identify any photo in our system, we can append shard number with each PhotoID.
- Each DB shard can have its own auto-increment sequence for PhotoIDs, and since we will append ShardID with each PhotoID, it will make it unique throughout our system.
- Handling hot users could become a problem, since they have many followers and any post they publish will make the corresponding shard hot.
- Some users will have a lot of photos compared to others, leading to a non-uniform distribution of data.
- What if we cannot store all pictures of a user on one shard? If we distribute photos of a user onto multiple shards, will it cause higher latencies?
-
Storing all pictures of a user on one shard can cause issues like unavailability of all of the user’s data if that shard is down or higher latency if it is serving high load.
- Sharding by PhotoID
- If we can generate unique PhotoIDs first and then find shard number through PhotoID % 100,000, this can solve above problems seen when sharding by UserID. We would not need to append ShardID with PhotoID in this case as PhotoID will itself be unique throughout the system.
- How can we generate PhotoIDs? Here, we cannot have an autoincrementing sequence in each shard to define PhotoID since we need to have PhotoID first to find the shard where it will be stored. One solution could be that we dedicate a separate database instance to generate auto-incrementing IDs. If our PhotoID can fit into 64 bits, we can define a table containing only a 64 bit ID field. So whenever we would like to add a photo in our system, we can insert a new row in this table and take that ID to be our PhotoID of the new photo.
- However, relying on a single key generating DB introduces a single point of failure. One potential workaround involves having two separate databases, each responsible for generating even and odd numbered IDs respectively. We can place a load balancer in front of both databases to distribute traffic between them using round robin methodology, managing downtime effectively. Although these servers may operate out of sync, with one generating more keys than the other, it won’t impact the system’s functionality.
- If we are anticipating huge growth in our data storage requirements, we can start with a large number of logical partitions, with multiple partitions residing on a single physical database server to start with. This gives us the flexibility to migrate certain logical partitions from it to another server, when the server has a lot of data.
Monitoring
It’s crucial to monitor our systems continuously. We should constantly collect data to get an instant insight into our system health and performance. We can collect following metrics/counters:
- New posts per day/second, what is the daily peak?
- News feed delivery stats, how many posts per day/second our service is delivering.
- Average latency experienced by users when refreshing the news feed.
By monitoring these, we can improve our services/infrastructure based on actual user data.